[Introduction]
LLM은 왜 시계열 예측에서 잘 안 맞을까?
최근 대규모 언어 모델(LLM)이 다양한 분야에서 강력한 성능을 보이면서, 시계열 예측(Time Series Forecasting) 분야에서도 LLM을 활용하려는 시도가 활발해지고 있다. 특히 텍스트는 뉴스, 리포트, 설명적 맥락 등 풍부한 정보를 담고 있기 때문에, 단순한 숫자 시계열만으로는 포착하기 어려운 고수준 의미 정보를 보완해 줄 수 있다.
하지만 문제는 LLM은 텍스트에 최적화된 모델이며, 시계열 데이터는 연속적이고 정밀한 수치 패턴을 가진다. 이 둘을 그대로 결합하면 다음과 같은 문제가 발생한다.
- 의미적 불균형(Semantic Imbalance): LLM은 숫자를 “연속 값”이 아닌 “토큰”으로 인식하여, 미세한 변화나 패턴을 제대로 반영하지 못한다.
- 분포적 불균형(Distribution Imbalance): 시계열 임베딩은 정규화되어 분산이 작은 반면, 텍스트 임베딩은 분산이 커서 결합 시 텍스트가 학습을 지배하게 된다.
기존 LLM 기반 시계열 모델들은 이 문제를 충분히 해결하지 못했고, 결과적으로 텍스트가 시계열을 압도하는 현상이 발생했다.
이 논문은 이 근본적인 문제를 “LLM을 쓰지 말자”가 아니라 “LLM을 제대로 쓰자”는 관점에서 접근한다.
[Methodology]
핵심 아이디어: 두 모달리티를 분리하고 균형 있게 정렬하자
모델은 크게 두 개의 브랜치와 균형 정렬 모듈로 구성된다.
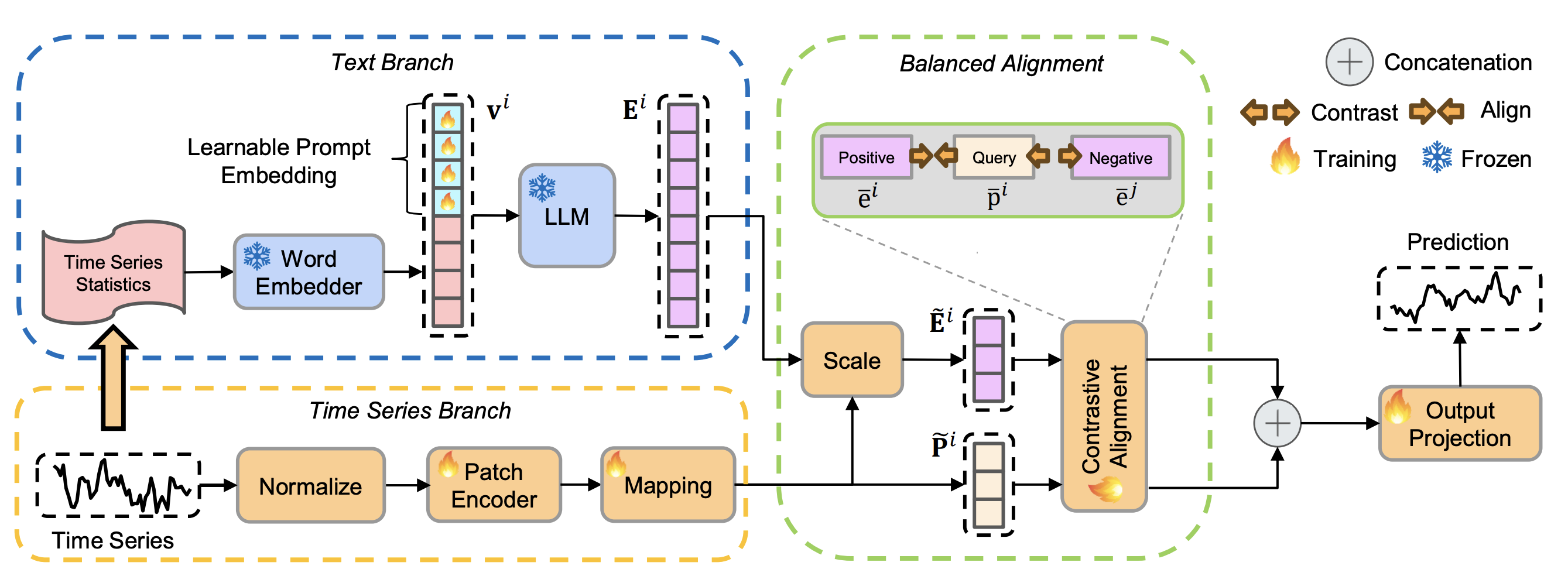
Time Series Branch
이 브랜치는 숫자 시계열의 구조적 패턴을 책임진다.
- RevIN 정규화
- 각 변수별 분포 변화를 완화하여 안정적인 학습을 유도한다.
- Patch 기반 인코딩지역적 패턴과 장기 의존성을 함께 학습한다.
- PatchTST 방식으로 시계열을 작은 패치 단위로 나누어
- LLM 차원으로 매핑
- 이후 텍스트 임베딩과 결합하기 위해 차원을 맞춘다.
Text Branch
텍스트 브랜치는 LLM의 강점을 안전하게 활용하는 부분이다. 핵심 전략은 원시 시계열을 LLM에 직접 넣지 않는 것이다. 대신 다음과 같은 통계 요약 정보를 텍스트 프롬프트로 만든다.
- 최소값 / 최대값 / 중앙값
- 전체 추세 (상승 / 하락)
- FFT 기반 상위 lag 정보
이 통계 프롬프트에 학습 가능한 soft prompt를 결합해 고정된 GPT-2 모델에 입력한다.
결과적으로 LLM은“이 시계열은 대략 이런 성격을 가진다”라는 의미적 요약 정보만 추출하게 된다.
Balanced Alignment
1. Horizon-aware Scaling
예측 길이(H)가 짧을수록 텍스트의 영향은 줄이고, 길수록 텍스트의 역할을 키운다.
이를 위해
- 텍스트 임베딩 토큰을 예측 길이에 따라 선별적으로 truncation
- 텍스트 임베딩의 분산을 시계열 임베딩 분산에 맞게 스케일링
2. Contrastive Semantic Alignment
같은 샘플의 시계열 임베딩, 텍스트 임베딩은 가깝게, 다른 샘플과는 멀어지도록 InfoNCE 기반 대조 학습을 수행한다.
Prediction
정렬된 텍스트 임베딩과 시계열 임베딩을 단순 concatenation 후 가벼운 projection head로 예측을 수행한다.
[Experiments]
데이터셋
- ETTh1, ETTh2, ETTm1, ETTm2
- Weather, Exchange
비교 모델
- LLM 기반: Time-LLM, UniTime, TimeCMA, GPT4TS
- Non-LLM 기반: PatchTST, iTransformer, DLinear, TimesNet
Long-term Forecasting 결과
- 대부분의 데이터셋과 예측 길이에서 MSE / MAE SOTA 또는 준-SOTA
- 기존 LLM 기반 모델 대비 평균적으로 8~11% 오류 감소
특히 긴 예측 구간일수록 텍스트 통계 정보의 장점이 더 명확하게 드러난다.
Few-shot Forecasting 결과
- 학습 데이터 10%만 사용한 환경에서도 강력한 성능
- LLM의 일반화 능력을 균형 있게 활용했을 때 효과가 극대화됨을 입증
[Conclusion]
본 논문은 LLM 기반 시계열 예측에서 발생하는 의미적·분포적 모달리티 불균형 문제를 핵심 한계로 지적하고 이를 해결하기 위해 BALM-TSF라는 이중 브랜치 구조를 제안한다. 원시 시계열은 전용 인코더로 처리하고 시계열 통계 정보를 텍스트 프롬프트로 요약하여 고정된 LLM에 입력함으로써 두 모달리티를 명확히 분리한다. 이후 예측 길이에 따라 텍스트 임베딩을 조절하는 horizon-aware scaling과 대조 학습 기반 정렬을 통해 텍스트와 시계열 표현을 균형 있게 결합한다. 이러한 설계는 텍스트가 학습을 지배하는 기존 LLM 기반 접근의 문제를 효과적으로 완화한다는 점에서 방법론적 강점이 있다. 반면 텍스트 브랜치가 단변량 통계 요약에 의존하기 때문에, 복잡한 외부 맥락이나 변수 간 상호작용을 충분히 반영하지 못하는 한계가 존재한다. 따라서 향후 연구에서는 보다 풍부한 텍스트 정보나 다변량 통계, 외부 지식의 통합을 통해 확장 가능성이 남아 있다.