[Background]
OneFitsAll
OneFitsAll은 GPT4TS라고도 불리며 인스턴스 정규화와 패칭을 적용한 후 선형 변환을 적용한다. 이후 언어 모델(GPT-2)이 이를 입력으로 받아 처리하며 예측한다. 아래에서 언급할 TimeLLM방식과 비슷하지만 시계열 데이터를 텍스트로 정렬하는 과정이 없고 TimeLLM의 경우 백본 모델이 사전학습된 언어 모델을 사용한 점이 다른 점이다.
TimeLLM
TimeLLM에 대한 자세한 설명은 아래 링크를 참고바란다.
https://myownproject.tistory.com/51
[Paper Review]Time-LLM: Time Series Forecasting By Reprogramming Large Language Models
[Background]● 왜 TS에는 LLM에 관한 연구가 많이 진행되지 않았는가? TS의 특징으로 인하여 Pre-training을 수행하는 것이 어렵다. TS 데이터로 Foundation 모델을 학습시킬 많은 양의 데이터를 구하기
myownproject.tistory.com
LLaTA
LLaTA는 입력된 시계열 데이터를 각 채널을 하나의 토큰으로 간주하여 임베딩하는 방식을 사용한다. 이 모델의 구조는 두 개로 나뉜다.
- Textual Branch
- Cross Attention을 사용하여 시계열 표현을 언어 모델의 저차원 단어 임베딩과 정렬한다.
- 이후 정렬된 표현을 사전 훈련된 언어 모델에 입력하여 Textual Prediction을 생성한다.
- Temporal Branch
- 입력된 시계열 데이터를 기반으로 사전 훈련된 언어 모델의 Low Rank Adapter(LoRA)를 학습한다.
- 이를 통해 Temporal Prediction을 생성하며 최종적으로 추론에 사용된다.
또한 두 브랜치에서 생성된 표현들이 유사하도록 강제하는 추가적인 손실 항목이 포함되어 모델이 두 가지 정보를 동시에 학습하도록 설계되어 있다.
[Summary]
본 논문에서는 시계열 분석을 위해 LLM을 사용하는 기존 연구들을 분석하였고 그 결과, LLM을 제거하거나 간단한 Attention Layer로 대체하여도 성능이 떨어지지 않으며 오히려 더 좋은 성능을 보여주는 경우도 있다는 점을 발견하였다고 한다.
해당 주장을 입증하기 위해 본 논문에서는 세 가지 인기 있는 LLM 기반의 시계열 예측 모델을 평가하고 LLM을 제거하거나 단순한 대체 모델을 적용한 후 성능을 비교하는 실험을 수행했다.
[실험 환경 및 설정]
본 논문에서는 비교를 위해 [Background]에서 설명한 세 모델을 사용하였다. 논문에서는 이 모델들이 정말로 효과적인지 검증하기 위해 기존 LLM 모델에서 LLM을 제거하거나 대체하는 Ablation 실험을 진행하였다.
Ablation 방법
- without LLM : LLM을 완전히 제거하거 입력 데이터를 최종 레이어로 전달
- LLM2Attn : LLM을 제거하고 대신 단순한 Self-Attention 레이어를 추가
- LLM2Trsf : LLM을 제거하고, Transformer Block 1개로 대체
사용한 데이터셋
- ETTh1 & ETTh2 : 1시간 단위로 측정된 전력 변압기 데이터
- ETTm1 & ETTm2 : 15분 단위로 측정된 전력 변압기 데이터
- Traffic : 1시간 단위로 측정된 샌프란시스코 교통량
- Electricity : 1시간 단위로 측정된 전력 소비량 데이터
- Weather : 10분 단위로 측정된 미국 기후 데이터
- Illness : 1주 단위로 측정된 독감 발생률 데이터
- Exchange Rate : 1일 단위로 측정된 환율 데이터
- Covid Deaths : 1일 단위로 측정된 코로나19 사망자 수 데이터
- Taxi : 30분 단위로 측정된 뉴욕 택시 승객 수 데이터
- NN5 : 1일 단위로 측정된 영국 ATM 현금 인출 데이터
- FRED-MD : 1개월 단위로 측정된 미국 경제 지표 데이터
LLM 기반 모델과 Ablation 모델 비교 및 실험
- 기존 LLM 모델의 결과를 재현하여 비교
- Ablation 모델을 적용한 후 성능을 비교
- 훈련 및 추론 시간, 모델 파라미터 수 등을 비교하여 LLM 사용의 효율성을 평가
본 논문에서는 위 실험을 통해 LLM이 시계열 예측에서 실제로 의미 있는 역할을 하는지, 혹은 불필요한 계산 비용을 증가시키는 지만을 확인하는 것이 본 논문의 목적이다.
[Results]
본 논문에서는 아래와 같은 연구 질문을 중심으로 실험을 설계하고 진행했다.
[실험 수행과정]
- LLM이 시계열 예측 성능 향상에 기여하는가?
- LLM 기반 모델은 계산 비용을 감수할 만큼 가치가 있는가?
- 사전 훈련된 LLM이 시계열 예측에 도움이 되는가?
- LLM은 시계열 데이터의 순차적 의존성을 학습하는가?
- LLM은 Few-shot 환경에서 도움을 줄 수 있는가?
- LLM 기반 모델의 성능은 어디에서 오는가?
1. LLM이 시계열 예측 성능 향상에 기여하는가?
- LLM을 제거하거나 단순한 Attention Layer 또는 Transformer Block으로 대체하는 실험을 진행했다.
- 선정한 세 개의 모델을 사용하여 13개의 시계열 데이터셋에서 평가를 수행했다.
[결과]
- LLM을 제거한 모델이 더 나은 성능을 보이는 경우가 많았다.
- Ablation 후 성능이 유지되거나 향상되는 것을 보여주었다.
- Time LLM의 경우, 26개의 실험에 대해서 모두 Ablation 한 것이 더 좋은 성능을 보여주었다.(LLaTA는 26개 중 22개, OneFitsAll은 26개 중 19개에서 Ablation 한 것이 더 좋은 성능을 보여줌)
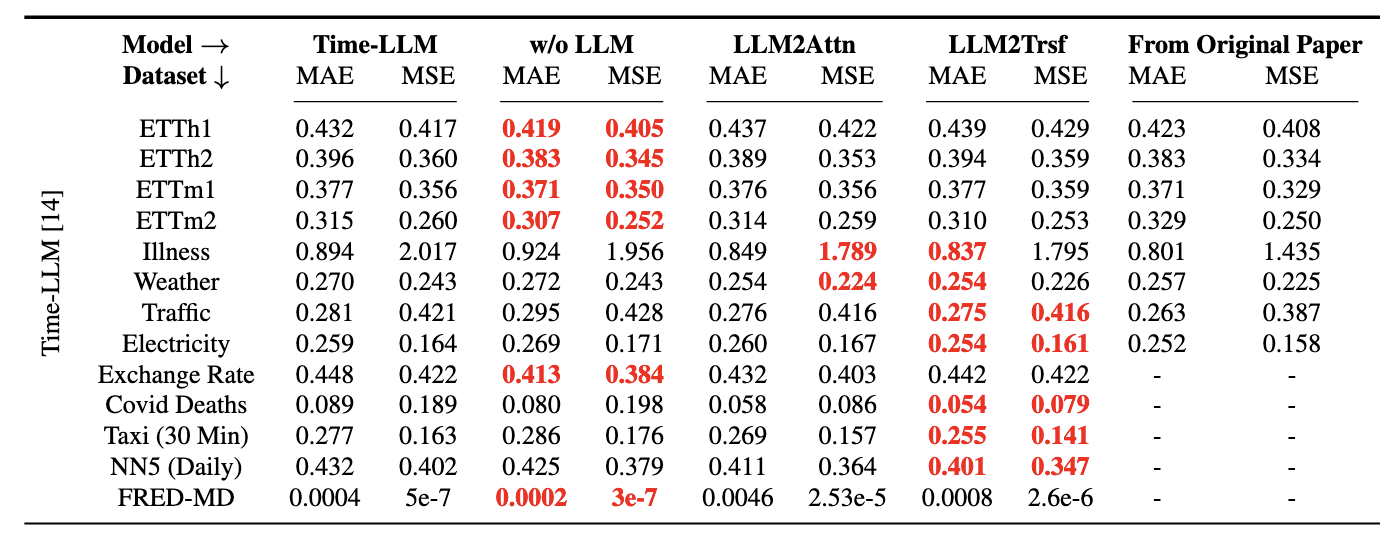
위 실험을 통해 LLM은 시계열 예측 성능 향상에 거의 도움이 되지 않았다고 결론 지을 수 있다.
2. LLM 기반 모델은 계산 비용을 감수할 만큼 가치가 있는가?
- 훈련 시간과 추론 속도를 비교하여 LLM의 계산 비용을 평가했다.
- 세 모델과 세 모델의 Ablation 모델의 훈련 시간과 파라미터 수를 비교했다.
[결과]
- LLM을 포함한 모델은 훈련 시간이 최대 1000배까지 증가했다.
- Time-LLM의 경우, 훈련 시간이 3003분, Ablation 모델은 2.17분으로 큰 차이를 보였다.
- LLM을 포함한 모델은 추론 속도도 최대 28배 느렸다.
- 하지만 Ablation 모델들은 연산량이 줄어들면서 성능 저하는 없었다.
3. 사전 훈련된 LLM이 실제로 도움이 되는가?
- LLM의 사전 훈련이 시계열 예측에 도움이 되는 지 실험을 통해 확인했다.
- 실험은 4 가지로 나누어서 수행했다.
- Pretrain + Finetune : 기존 모델들의 수행 방식
- Random Initialization + Finetune : 사전 학습을 제거하고 처음부터 학습
- Pretrain + No Finetuning : 사전 학습된 LLM을 그대로 사용하고, 추가 학습 없이 평가
- Random Initialization + No Finetuning : 랜덤 초기화된 모델을 그대로 평가
[결과]

- 사전 학습이 없는 모델(2)이 기존 방식보다 더 좋은 성능을 보이는 경우가 많았다.
4. LLM이 시계열 데이터의 순차적 의존성을 학습하는가?
- 시계열 데이터를 무작위로 섞어서 예측의 성능 변화를 확인했다.
- 실험은 4가지로 나누어 수행했으며 4가지 입력 변환 실험을 수행했다.
- sf-all : 전체 시계열 데이터를 랜덤하게 섞는다.
- sf-half : 처음 절반 데이터만 랜덤하게 섞는다.
- ex-half : 앞뒤 절반 데이터를 바꾼다.
- masking : 일부 데이터를 마스킹한다.
[결과]

- LLM이 포함된 모델과 포함되지 않은 모델 모두 데이터를 섞은 후 성능의 변화가 거의 없었다.
- 따라서 LLM은 시계열 데이터의 순차적 관계를 학습하는 데 효과적이지 않다고 결론지었다.
5. LLM이 Few-shot 환경에서 도움이 되는가?
- 데이터의 10%만 사용해서 Few-shot 성능을 평가했다.
- 기존 모델과 Ablation 모델을 비교했다.
[결과]
- LLM이 없는 모델이 기존 모델과 비교했을 때 동일하거나 더 좋은 성능을 보여줬다.
- LLaMA 기반의 Time-LLM모델의 경우 LLM을 제거한 모델과 비교했을 때 비슷한 성능을 보여줬다.
- GPT-2 기반의 LLaTA 모델의 경우, LLM을 제거한 모델이 거의 대부분의 실험에서 더 좋은 성능을 보여줬다.
- 따라서 Few-shot 환경에서도 LLM은 시계열 예측에 도움이 되지 않는다고 결론지었다.
6. LLM 기반 모델의 성능은 어디에서 오는가?
- 다양한 시계열 인코딩 방법을 실험하여 LLM을 대체할 수 있는 대안을 검토했다.
- 본 논문에서는 패칭 기법과 Attention을 조합한 간단한 모델, "PAttn"을 이용하여 실험을 진행했다.
[결과]
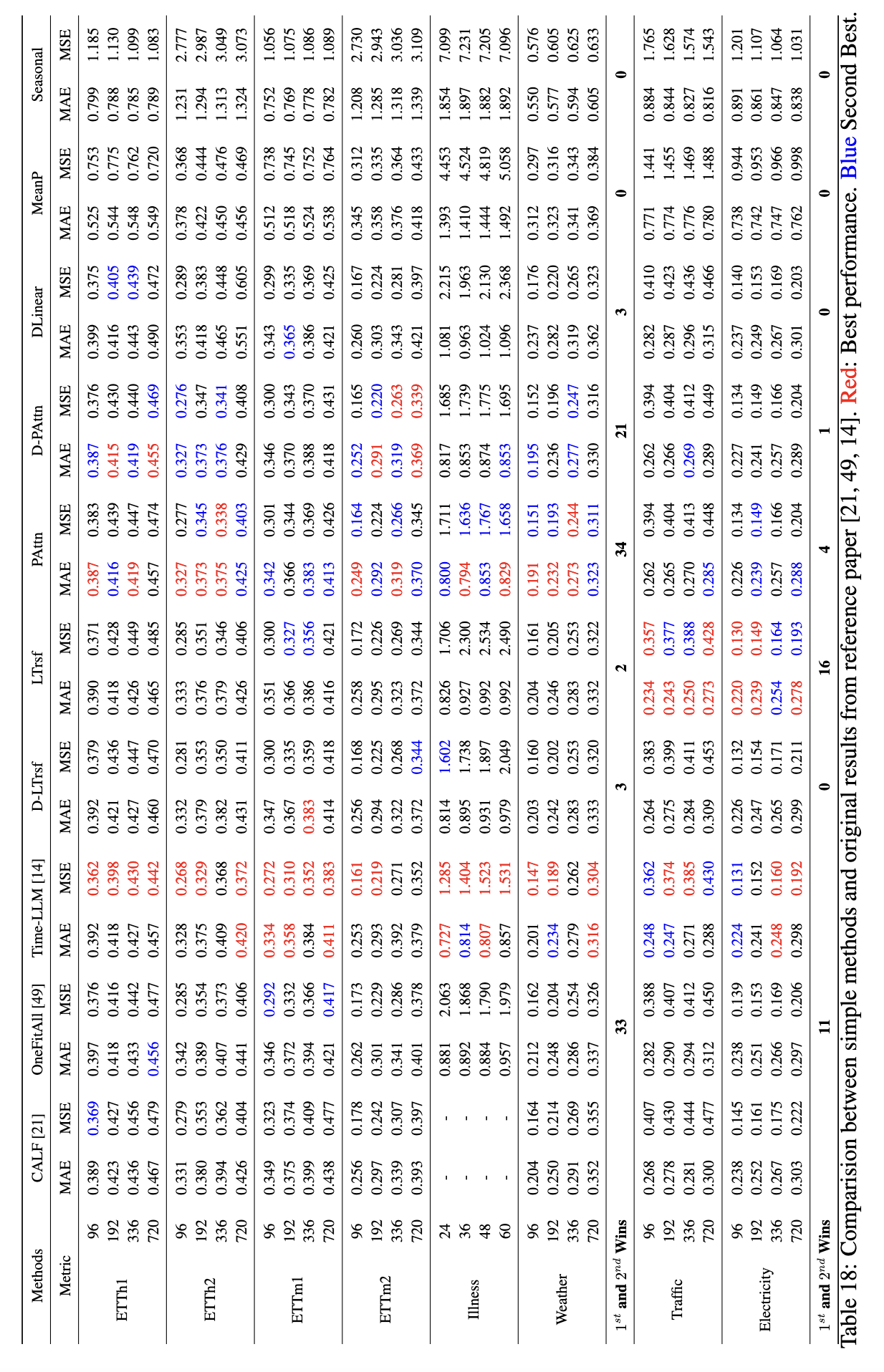
- PAttn 모델이 LLM과 유사한 성능을 보여줬다.
- 일부 실험에서는 PAttn을 사용한 것이 LLM을 사용한 모델보다 더 좋은 성능을 보여줬다.
- 따라서 본 논문에서는 LLM 없이도 시계열 예측을 수행하는 것이 충분이 가능하다는 것을 보여주었다.
[Conclusions]
본 논문은 과연 시계열 예측을 수행하는 과업에 거대 언어 모델을 사용하는 것이 실제도 도움이 되는 것인지에 대한 근본적인 의문을 제기하였다. 트랜스포머 모델이 컴퓨터 비전 분야에서 좋은 성능을 보이면서 이 모델을 활용하여 다른 분야에서도 사용하려는 움직임이 많아졌고, 시계열 예측 분야 또한 트랜스포머 모델을 변형하여 과업을 수행하려는 다양한 노력들이 있었다.
본 논문은 시계열 예측에 정말로 LLM이 도움이 되는지 판단하고자 다양한 실험을 진행하였다. 성능적인면 뿐만 아니라 비용적인 면에서도 비교해보았을 때 시계열 데이터 예측에 LLM을 사용하는 것이 오히려 좋지 않은 성능을 보여주었다는 것을 실험을 통해 증명하였다. LLM의 비용보다 훨씬 적은 비용으로 LLM을 사용한 모델과 거의 비슷한 성능을 낸다는 것이 큰 발견이었다고 생각한다. 다만, 본 논문에서 제시한 "PAttn" 방법으로 실험을 수행한 결과를 보았을 때, 과연 LLM보다 더 좋은 성능인 것인지에 대한 의문이 든다. 결과를 보면, Time-LLM 모델과 비교했을 때, Top2의 비중은 "PAttn"이 높지만 성능적으로 우수한 점은 Time-LLM 모델이 더 우수한 것을 확인할 수 있기 때문이다. LLM을 사용하는 것이 비용적으로 큰 부담이지만, 현재에도 꾸준히 연구중인 언어 모델을 이용하여 더 발전된 LLM을 기반으로 시계열 예측을 수행하게 된다면 기존보다 더 좋은 성능을 보여줄 수 있다고 생각한다.

