[Summary]
Introduction
시계열 이상탐지에 LLM을 활용하고자 한 연구들이 최근 활발히 연구되고 있다. 하지만 LLM을 활용하는 시계열 이상탐지는 방대한 학습 데이터를 사용하고, 설명하지 않는 Black Box로써 추론을 수행한다. 또한 추론한 결과에 대한 설명이 부족하여 탐지한 이상에 대한 근거가 없는 점은 딥러닝 기반 시계열 이상탐지 방법들이 제안되어도 실제 산업에 적용하기 어려운 이유이다. 따라서 본 논문에서는 LLMAD 모델을 제안한다.
Contributions
- 정확한 TSAD를 수행하며 예측한 답에 대한 결과를 설명하는 LLM 기반 프레임워크인 LLMAD를 제안한다.
- Data Context, 도메인 지식, 인간의 전문성을 주입하여 성능과 해석력을 향상시켰다.
- 세 개의 데이터셋으로 실험을 진행하였고 제안한 모델이 높은 정확도와 해석을 적절한 cost 내에서 수행했다.
- 제안한 방법을 CompanyX라는 회사에서 실제 사용하고 있다. 실제 산업에서 이상에 대한 통찰력을 제공할 뿐만 아니라 엔지니어의 필요도도 감소시켰다.
Methodology
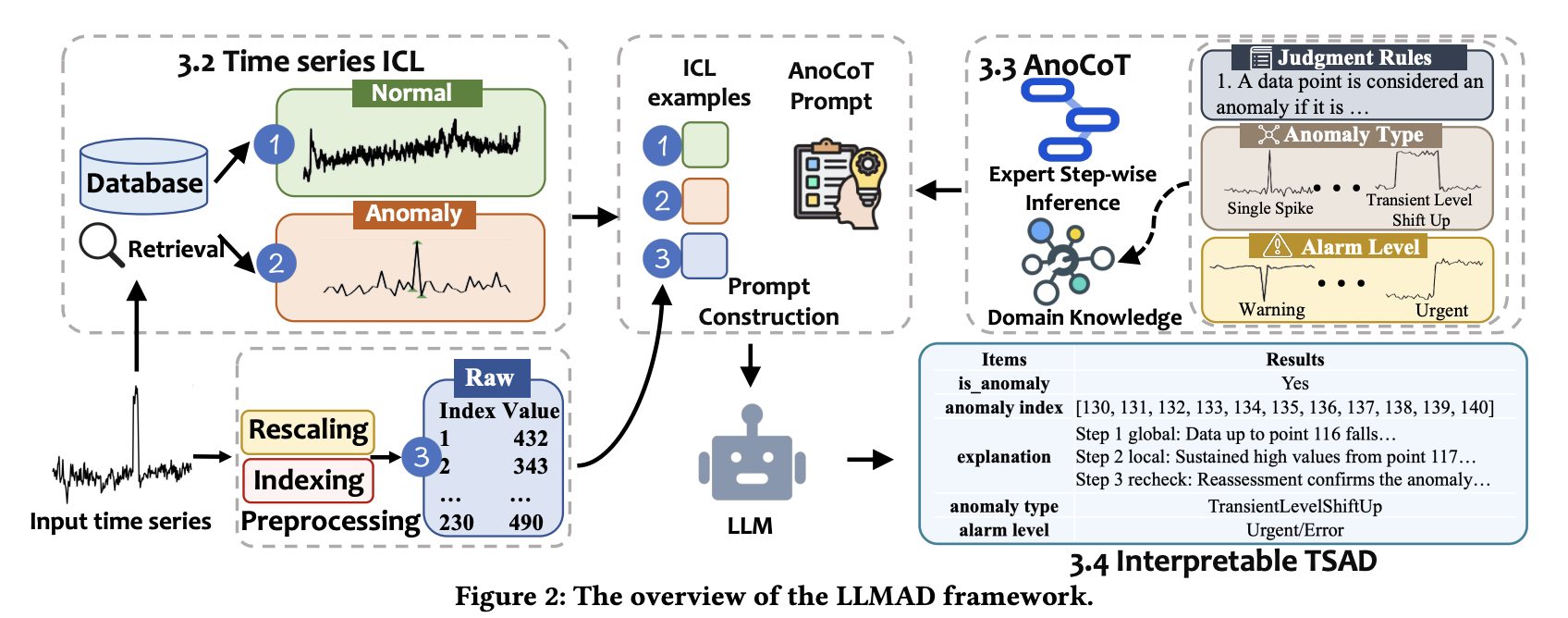
Time Series In-Context Learning

LLM이 시간적 데이터 패턴을 이해하도록 정상과 이상 시계열의 예시를 함께 프롬프트에 포함시켜 LLM이 그 경계를 스스로 문맥속에서 학습하게 하는 방식이다. 시계열 데이터베이스를 먼저 구성하는데, 정상 시계열 데이터베이스와 이상 시계열 데이터베이스를 따로 만들고 입력 시계열 T를 입력받으면 FastDTW를 사용하여 유사한 정상시계열 K개와 유사한 이상 시계열 K개를 각각 DB에서 검색한다. 검색된 유사한 정상과 비정상 데이터와 함께 원본 정보도 입력되고 AnoCoT 프롬프트와 함께 LLM에 제공된다. 이때 선택되는 정상, 비정상 데이터는 정상 1개, 비정상 2 개를 선택하여 프롬프트를 구성한다. 이는 실험을 통해 정해졌다고 한다.
AnoCoT
실제 시계열에 따라 다른 판단 기준이 있기 때문에 이상으로 볼 수 있는 Anomaly Type과 Alarm Level, Judgement Rules를 추가하여 실제 산업의 지식을 기반으로 Chain-of-Thought 추론을 통해 판단할 수 있도록 설계하였다. 크게 Domain Knowledge Injection, Expert Step-wise Inference 두 단계로 이루어져 있다. Domain Knowledge Injection 단계에서는 정상과 이상을 구분하는 규칙, 이상 유형의 정의, 경고 단계 정의를 통해 LLM에게 이상과 정상을 판단하는 기준을 알려주고 해당 이상이 어떤 유형인지, 어떤 위험 이상에 대한 단계 정보를 주입한다. Expert Step-wise Inference 단계에서는 실제 LLM이 어떤 방향으로 이상을 탐지해야하는지를 정의한다. 먼저, Global Trend Assessment 단계로 시계열의 전반적인 추세를 분석한다. 이후 Local Anomaly Assessment 단계로 단기 급변과 같은 국소 이상을 탐지한다. 마지막은 Reassessment 단계로 이전 단계에서 탐지된 이상을 재검증한다.
[Experiments]

Performance Comparison

실험 결과를 보면 전반적으로 나쁘지 않은 성능을 보인다. 다만 성능적으로 강조하려는 것보다 학습 없이 Retrieval을 사용하여 효율적으로 추론할 수 있다는 점에 주목할 수 있다.

그리고 LLM마다 성능 차이가 좀 많이 나는데 이는 LLM의 추론 능력에 직접적으로 성능이 비례함을 보인다.
Interpretability Evaluation
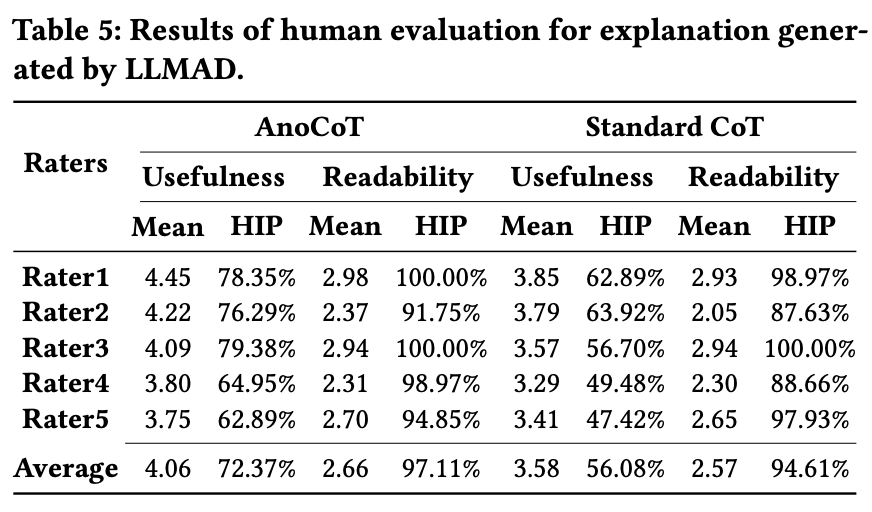

두 실험은 LLM이 이상에 대해서 어떻게 설명하는지, 그 설명 능력을 평가한 실험이다. 첫 번째 표는 본 논문에서 제안한 AnoCoT와 일반적인 CoT와의 성능을 평가한 것으로 실험 결과 AnoCoT가 더 우수한 성능을 보여주었다. 두 번째 표는 각 백본에 따른 이상 유형 분류에 대한 정확도를 평가한 실험으로 여전히 GPT4가 우수한 성능을 보여준다.
이외 Cost 관련 실험, 시각화 부분에 대한 결과는 본 논문을 직접 참고하길 바란다.
[Results]
본 논문은 시계열 데이터 이상탐지를 위해 학습이 필요 없는 LLM을 활용한 이상탐지 모델인 LLMAD를 제안하였다. 데이터베이스에서 Retrieval하여 유사한 정상, 이상 데이터를 샘플링하고 샘플과 함께 LLM에게 입력한다. 이때, AnoCoT를 활용한 프롬프트를 구성하여 질의하고 LLM은 이를 기반으로 추론하여 이상에 대해 추론하고 어떤 이상인지 설명한다. LLM을 적극적으로 활용한 방법이라고 생각하지만 이 데이터베이스에서 Retrieval하는 구조가 만약 다양한 유형의 이상이 존재하고, 서로 다른 데이터 간의 정상과 이상의 구분이 동일하지 않기 때문에 프롬프트를 통해서 이걸 구별하기에는 Retrieval하는 방식에서는 한계점이 존재한다고 생각한다. Retrieval 결과에 정상, 이상이 서로 뒤바뀐 경우가 나타날 경우도 존재할 것 같은데 이에 대해서 어떻게 처리되는지는 제안점이 약하다고 생각한다. 다만 특정 도메인에 특화된 산업군에서 적용하기에 비용이 적게 드는 좋은 방법이라고 생각한다.
최근에 LLM을 활용한 이상탐지 모델이 많이 제안되고 있는데 이 부분에 대해서 좀더 논문을 읽어봐야겠다.
