[Background]
● LLM의 한계
초기의 LLM은 단순히 언어 작업에만 초점을 맞추어 개발되었다. 이러한 점에서 현재의 최첨단 LLM인 ChatGPT는 매우 뛰어난 성능의 Tool 사용 능력을 보여주었지만 ChatGPT는 알다시피 폐쇄 소스라 변경 및 발전시키는 것에 있어서 한계가 명확하다. 이러한 점에서 오픈 소스 LLM인 LLaMA를 fine-tuning하여 Tool을 사용하는 것에 최적화하도록 하면 고수준 작업을 수행하는 것에 있어서 LLM이 더 발전할 수 있다고 주장한다.
● 이전 연구의 한계점
1. Limited APIs
진짜 현실 세계의 API들을 사용하는 것에 실패하거나 작은 범위에 국한된 API들을 사용하여 다양성이 떨어졌다.
2. Constrained Scenario
기존의 연구들은 하나의 도구만 포함하는 명령어로 제한되어 있었다. 하지만 실제 시나리오에서는 복잡한 작업을 해결하기 위해 다양한 도구를 함께 사용해야 할 수 있다. 또한 기존 연구들은 사용자가 주어진 명령어에 대한 이상적인 API 세트를 미리 수동적으로 지정한다고 가정하는 경우가 많다. 이를 실제 API 컬렉션에서 적용한다는 것은 불가능하다.
3. Inferior planning and reasoning
아래 두 가지 추론 방법은 언어 모델이 더 복잡한 문제를 해결하거나 추론할 때 유용한 두가지 기법이다.
○ Chain of Thought(CoT)
모델이 답을 도출하는 과정을 일련의 논리적 단계로 설명하는 방식이다. 즉, 언어 모델이 단순히 최종 답만 제공하는 것이 아니라, 중간 추론 과정을 문장 형태로 설명하는 것이다. 이 방법은 특히 복자한 문제나 여러 단계를 거쳐야 하는 계산에서 유용하다. 모델이 각 단계에서 추론의 흐름을 명시적으로 표현할 수 있도록 도와주기 때문이다.
○ Reasoning and Acting(ReAct)
언어 모델이 추론을 하고 그에 맞춰 행동하는 방식이다. 모델이 추론을 통해 문제를 해결하기 위한 행동을 동시에 수행한다. 여기서 행동은 API호출, 환경 상호작용, 외부 도구 활용 등과 같은 실제 행동을 포함할 수 있다. 이 방법은 모델이 외부 환경과 상호작용할 수 있도록 도움을 주고 단순한 추론 뿐만 아니라 실제 행동을 기반으로 문제 해결을 지원한다. 또한 도구 사용 및 상호작용이 필요한 문제에서 강력한 성능을 발휘한다.
이 두 방식은 문제 해결 과정에서 가지는 오류 전파와 제한된 탐색이라는 두 한계점을 가지고 있다. 소개할 논문에서는 이 한계점을 개선한 방법인 DFSDT에 대해 설명한다.
[Summary]

이 그림은 본 논문에서 얘기하는 ToolLLaMA의 과정을 나타낸 그림이다. 왼쪽 구조표는 ToolLLaMA를 학습하는 과정이고 오른쪽은 사용자가 ToolLLaMA를 사용하는 과정에 대해 나타낸 것이다.
● ToolLLaMA Training
먼저 ToolBench를 구성해야한다. ToolBench를 구성하는 것은 크게 3단계로 나뉜다. API 수집, 명령 생성, 그리고 해결 경로 annotation. 모든 과정은 ChatGPT(3.5-turbo-16k)를 기반으로 진행하였다.
1. API 수집
○ RapidAPI

이 그림은 RapidAPI의 구조를 나타낸 것이다. RapidAPI는 개발자가 수천 개의 실제 API와 연결하여 다양한 서비스를 애플리케이션에 통합하는 프로세스를 간소화한 API 마켓플레이스이다. RapidAPI의 모든 API는 스포츠, 금융, 날씨 등 49개의 세분화된 카테고리로 분류된다. 카테고리는 API를 가장 관련이 높은 주제와 연관시킨다.
그림과 같이 각 Tool은 여러 개의 API로 구성될 수 있다. 각 Tool에 대해 도구의 이름과 설명, 호스트의 URL, Tool에 속하는 모든 사용 가능한 API 등 다음 정보를 크롤링한다. 이러한 데이터는 LLM이 zero-shot 방식으로도 API를 이해하고 효과적으로 사용할 수 있는 귀중한 리소스 역할을 한다.
ToolLLM에서 처음에는 RapidAPI에서 10,853개의 Tool(53,190개의 API)을 수집해서 실험을 진행했다. 하지만 API들 마다 품질과 신뢰성이 크게 다를 수 있다. 일부 API는 잘 유지 관리가 되지 않을 수 있다. 이에 따라 필터링 과정을 거쳐 고품질 Tool 3,451개(16,464개)만 보유하도록 한다.
2. 명령 생성

API를 샘플링한 후에 ChatGPT에 이러한 API에 대한 다양한 명령을 생성하도록 하였다. 현실 세계의 시나리오를 다루기 위해 단일 Tool 또는 다중 Tool 시나리오와 관련된 명령을 큐레이팅하여 모델이 하나의 도구와 상호 작용하는 것 뿐만 아니라 이를 결합하여 복잡한 작업을 수행하는 방법도 학습하도록 했다.
본 논문에서는 고품질 명령을 생성하기 위해 두 가지 중요한 속성을 제시한다. LLM이 광범위한 API 사용 시나리오를 처리하도록 훈련하여 일반화 가능성과 견고성을 높이기 위해 다양성과 여러 도구의 상호작용이 필요한 실제 상황을 반영하여 LLM의 실용적인 적용 가능성을 유연성을 개선하기 위해 멀티 tool 사용을 중요시한다.
API를 이용하여 명령을 생성하기 위해 먼저 전체 API 집합인 SAPI에서 일부 API들을 샘플링하여 작은 하위 집합 $S_{n}$을 만든다. 이 하위 집합에는 여러 API들이 포함된다. ChatGPT에게 이러한 API 기능을 이해하도록 하고, 그 후에 API를 포함하는 명령을 생성하고, 각 명령에 관련된 API들의 집합$S_{rel}$을 생성하게 한다. 즉, [$S_{rel1}$, $Inst_{1}$], [$S_{rel2}$, $Inst_{2}$], [$S_{rel3}$, $Inst_{3}$] ,... 와 같은 형태로 명령과 관련된 API들이 쌍으로 생성된다. 이러한 API 쌍은 나중에 API Retriever를 훈련시키기 위해 사용된다.
ChatGPT에 제공하는 프롬프트는 먼저 명령 생성 작업에 대한 일반적인 설명, 샘플링된 API 각각의 기능에 대한 상세한 설명, 세 가지 예시(seed1, seed2, seed3)로 구성된다. 여기서 세 가지 예시는 사람이 작성한 이상적인 명령 예시들이다. ChatGPT가 이러한 예시를 바탕으로 학습하여 더 나은 명령을 생성할 수 있도록 한다. 각 프롬프트는 12개의 단일 Tool 예시와 36개의 다중 Tool 예시로 구서오디며 매번 세 개의 예시가 무작위로 선택된다. 이 예시들은 사람이 작성한 것으로 ChatGPT의 동작을 규제하는 데 사용된다.
ChatGPT는 주어진 API들과 세 개의 예시를 바탕으로 명령과 관련된 API 쌍을 생성한다.

단일 Tool 명령은 각 Tool에 대해 순차적으로 명령을 생성한다. 여러 Tool을 사용하는 설정에서는 서로 관련없는 도구들이 샘플링될 가능성이 높기에 이때는 RapidAPI의 계층 정보를 활용한다. 즉, 같은 카테고리나 컬렉션에 속한 도구들을 선택하여, 서로 관련 있는 API들을 바탕으로 명령어를 생성하도록 한다. 이때 같은 카테고리 내 2개에서 5개의 tool을 선택한다.
이제 생성된 명령 세트로 존재하지 않는 API를 관련 API로 잘못 포함시킨 명령을 필터링한다. 그 결과, 총 200,000개의 유효한 명령과 관련 API 쌍을 수집했다. 여기에는 단일 Tool 설정 87,413개, 카테고리 내 다중 Tool 설정 84,815개, 컬렉션 내 다중 Tool 설정 25,251개의 인스턴스가 포함된다.
3. 해결 경로 annotation
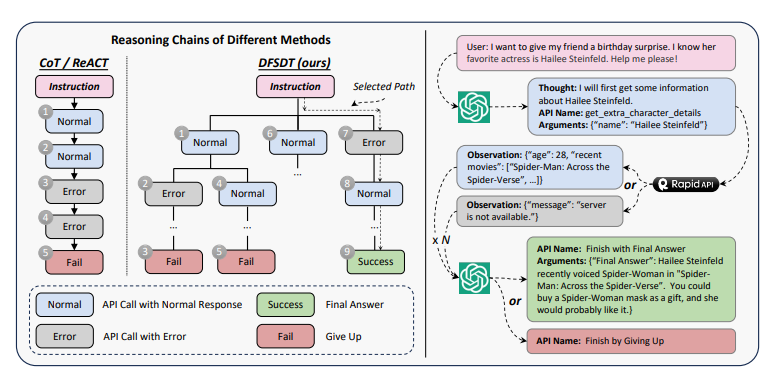
이제 생성한 명령을 기반으로 ChatGPT를 활용하여 해결 경로를 찾아낸다. 주어진 명령에 대해 ChatGPT는 유효한 API 순서를 찾아낸다. 이는 ChatGPT와의 다중 라운드 대화로 표현된다. 각 라운드에서 모델은 이전의 상호작용과 주어진 명령에 기초하여 다음 행동(API)를 생성한다. 각 행동은 "Thought : ..., API Name : ..., Parameters : ..." 형식으로 표현되는데 이 형식은 어떤 생각을 기반으로 어떤 API를 사용할지와 그 API에 필요한 매개변수를 포함한다. ChatGPT가 API를 잘 호출할 수 있도록 각 API를 특별한 함수로 취급하고 API 설명서를 ChatGPT의 함수 호출 기능으로 제공한다. 이를 통해 모델은 API를 어떻게 호출해야 하는지 이해할 수 있다.
ChatGPT가 명령을 처리하는 동안 샘플링된 API들은 사용가능한 함수로 제공된다. API 호출 순서를 끝내기 위해 두 가지 종료 함수를 정의한다.
○ Finish with Final Answer : 최종적으로 원래 명령어에 대한 답을 생성할 때 사용
○ Finish by Giving Up : 여러 번의 API 호출 시도 후에도 명령을 처리할 수 없을 때 사용
또한 Background에서 설명한 기존의 Inferior planning and reasoning의 문제점을 개선한 방법에 대해 설명한다.
CoT와 ReAct 기법은 다음과 같은 한계가 존재한다.
1. 오류 전파 : 잘못된 행동이 오류를 계속해서 퍼뜨리게 되어 모델이 잘못된 루프에 빠질 수 있다. 예를 들어, API를 잘못된 방식으로 반복 호출하거나, 존재하지 않는 API를 호출하는 등의 문제가 발생할 수 있다.
2. 탐색의 제한성 : CoT나 ReAct는 단일 방향으로만 탐색하므로 전체 행동 공간을 충분히 탐색하지 못하는 문제가 있다. 이러한 이유로 심지어 GPT-4도 종종 유효한 해결 경로를 찾지 못하는 경우가 발생한다.
● 깊이 우선 탐색 기반 결정 트리(DFSDT)
기존 CoT와 ReAct 기법의 한계로 결정 트리를 사용하여 탐색 공간을 확장하고 더 많은 해결 경로를 찾을 가능성을 높이도록 제안한다.
DFSDT는 모델이 여러 추론 경로를 평가하고, 유망한 경로를 계속 진행하거나 "Finish by Giving Up" 함수를 호출하여 현재 경로를 포기하고 새로운 노드를 확장하도록 만든다. 노드 확장 시, 모델이 이전에 생성된 노드 정보를 바탕으로 새로운 노드를 생성하도록 유도하여 탐색 공간을 확장한다. 여기서 DFS 방식을 사용하는 이유는 한 번의 유효한 경로만 찾으면 굳이 이어서 작업을 수행할 필요가 없기 때문이다. BFS 방식으로 사용할 시에는 과도한 API 호출 비용이 발생할 수 있기 때문에 적합하지 않다.
DFSDT를 사용하여 생성된 모든 명령에 대해 유효한 해결 경로를 찾는 과정을 수행하고, 그 중에서 통과된 경로 만을 유지하도록 한다. 이를 통해 최종적으로 126,486개의 명령과 해결 경로 쌍이 생성되었으며, 이는 ToolLLaMA를 훈련하는 데 사용된다.
[Results]
ToolLLM 프레임워크의 성능을 조사하기 위해 본 논문에서는 성능 평가와 함께 ToolEval, API Retriever, DFSDT의 우수성에 대해 설명하고 있다.
1. ToolEval
ToolEval은 AlpacaEval을 기반으로 개발된 ChatGPT를 활용한 평가 도구이다. API의 시간적 변화와 무한한 해결 경로 때문에 모든 명령에 대해 고정된 정답 경로를 설정하는 것을 불가능하므로, ToolEval을 통해 효율적으로 평가한다. ToolEval은 두 가지 평가 기준을 사용한다.
※ AlpacaEval : 언어 모델이 지시 사항을 어마나 잘 따르는지 평가하는 자동 평가 시스템이다. 이 시스템은 AlpacaFarm의 데이터셋을 사용하여 모델의 응답을 참조 응답과 비교하고 이를 통해 모델의 Win Rate를 계산하고 리더보드에서 모델을 순위별로 나열한다. AlpacaEval은 신뢰성, 속도 및 비용 효율성에서 높은 평가를 받으며 인간 annotation과도 밀접하게 일치한다.
- Pass Rate : 제한된 예산 안에서 주어진 명령을 성공적으로 완료한 비율을 측정한다. 이 지표는 LLM이 명령을 실행할 수 있는 능력을 평가하며, 이상적인 도구 사용을 위한 기본적인 요구사항을 나타낸다.
- Win Rate : ChatGPT 평가자에게 명령과 두 개의 해결 경로를 제공한 후, 어느 경로가 더 나은지 선택하게 한다. Win Rate는 어떤 경로가 더 적합한 지에 대한 ChatGPT의 선호도를 측정한다.
Pass Rate와 Win Rate에 대해 부록을 참고하여 더 설명해보겠다. 일단 명령은 두 가지로 분류될 수 있다.
Pass Rate 평가에 대한 규칙들
- 해결 가능한 명령(Solvable) : 제공된 Tool 중 하나가 명령을 해결하는 데 도움이 될 가능성이 있는 경우
- "Finish by Giving Up"으로 종료한 경우
- 모델이 모든 API를 충분히 시도한 후에도 도움이 되는 정보를 받지 못했다면 Pass로 간주된다.
- 모델이 몇 개의 API만 호출했거나 유효한 정보를 받았는데도 해결을 포기했다면 Fail로 간주된다.
- "Finish with Final Answer"로 종료한 경우
- API에서 유효한 정보를 제공하지 못했고, 모델이 모든 API를 시도했지만 최종 답변이 여전히 명령을 해결하지 못하거나 거부를 전달하면 Pass로 간주된다.
- 도구들이 유효한 정보를 제공했으나 최종 답변이 완전히 문제를 해결하지 못하거나 거부를 전달하면 Fail로 간주된다.
- 최종 답변이 원래 명령을 완전히 해결하면 Pass로 간주된다.
- 최종 답변이 명령을 해결했는지 여부를 판단할 수 없는 경우 Unsure로 간주된다.
- "Finish by Giving Up"으로 종료한 경우
- 해결 불가능한 명령(Unsolvable) : 제공된 API들이 모두 명령과 무관하거나, 명령 자체가 유효하지 않은 정보를 제공하는 경우
- "Finish with Final Answer"로 종료한 경우
- 최종 답변이 처음에 해결 불가능한 것으로 여겨졌던 명령을 해결했다면 Pass로 간주된다.
- 최종 답변이 거부를 전달하면 Pass로 간주된다.
- 모델이 잘못된 긍정 응답을 제공하고 거짓으로 작업을 완료했다고 주장하는 경우, Fail로 간주된다.
- "Finish by Giving Up"으로 종료한 경우
- 해결 경로는 Pass로 간주된다.
- "Finish with Final Answer"로 종료한 경우
Win Rate 평가 기준들
- 정보의 풍부함(Information richness) : 최종 답변이 명령에 필요한 모든 정보를 포함하고 있는지 평가한다. 더 풍부한 정보를 제공한 경로가 더 나은 것으로 평가된다. 비슷한 수준의 정보가 제공되었다면 무승부(tie)로 평가된다.
- 사실성(Factuality) : 최종 답변이 정확하게 어떤 작업이 수행되었는지, 어떤 부분이 실패했는지를 사실적으로 설명하는지 평가한다. 더 정확한 설명을 제공한 경로가 더 나은 것으로 평가된다.
- 추론(Reasoning) : 문제가 해결되지 않은 경우, 그 실패 이유를 얼마나 자세하고 정확하게 설명하는지 평가한다. 더 자세한 설명을 제공한 경로가 더 나은 것으로 평가된다.
- 중간 단계 달성(Milestone) : 해결 과정에서 얼마나 많은 중간 단계를 성공적으로 달성했는지를 계산한다. 더 많은 중간 목표를 달성한 경로가 더 나은 것으로 평가된다.
- 탐색(Exploration) : 해결 과정에서 더 많은 유용한 API를 시도했는지 평가한다. 더 많은 API를 시도한 경로가 더 나은 것으로 평가된다.
- 비용(Cost) : 동일한 수의 API를 사용한 경우, 중복 API 호출이 적을수록 더 나은 경로로 평가된다.
각 해결 경로에 대해 4회 이상의 예측을 생성한 후, 다수결 투표로 최종 Win Rate를 계산한다. 무승부 비율을 스일와 패배 비율로 나누어 표시하여 더 쉽게 결과를 해석할 수 있다.
본 논문에서는 ChatGPT 평가자와 인간 평가자가 Pass Rate와 Win Rate에서 얼마나 일치하는지를 비교하였다. 실험 결과, Pass Rate에서는 87.1%, Win Rate에서는 80.3%의 일치율을 보였다. 이는 ChatGPT 평가자가 인간 평가자와 유사한 평가 결과를 생성할 수 있음을 보여준다.
2. API Retriever
API Retriever는 주어진 명령에 맞는 관련 API를 찾아내는 기능을 한다. 이를 위해 Sentence-BERT를 사용하여 BERT 모델을 기반으로 API 검색기를 훈련한다.
※ Sentence-BERT
명령어와 API 설명을 임베딩하여, 이 두 임베딩의 유사도를 계산함으로써 관련 API를 찾아낸다. 이때 대조학습을 사용하여 각 명령어에 대해 관련된 API는 긍정 예시로, 관련 없는 API는 부정 예시로 학습시킨다.
API Retriever의 성능을 평가하기 위해 BM25와 OpenAI의 text-embedding-ada-001 같은 기준 모델과 비교한다. NDCG(정규화된 누적 순위 점수)라는 평가지표를 사용하여 API 검색 성능을 측정한다.
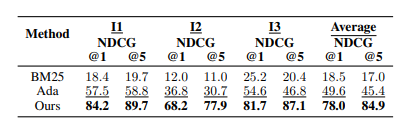
API 검색기의 성능 평가는 다음 그림에서 확인할 수 있듯이 모든 설정에서 기준 모델들보다 우수한 성능을 보였다. 특히 단일 Tool 명령에서의 NDCG 점수가 I2, I3보다 높았는데 이는 단일 Tool 검색이 다중 Tool 검색보다 더 간단하다는 것을 의미한다.
3. DFSDT
본 논문에서 새로 제안한 방식인 DFSDT이 ReAct보다 우수하다는 것을 설명하기 위해 Pass Rate(통과율)을 기준으로 평가하여 둘의 성능을 비교한다.

DFSDT에 대한 설명은 위의 내용을 참고해주길 바란다. 아무래도 DFSDT는 더 많은 OpenAI API 호출을 필요로 하기 때문에 ReAct와 공정하게 비교하기 위해 ReAct@N이라는 기준을 설정한다. ReAct@N은 ReAct를 여러 번 실행하여 DFSDT와 동일한 수준의 비용이 소모될 때까지 실행한 후, 유효한 해결 경로가 나오면 통과(pass)로 간주하는 방식이다.
위 표에서도 확인할 수 있듯이 DFSDT가 모든 시나리오에서 ReAct 및 ReAct@N보다 더 높은 성능을 보였다. DFSDT는 동일한 예산을 기준으로 했을 때, 더 많은 명령을 annotate할 수 있었으며, 이를 통해 전체 annotate 비용을 절감할 수 있었다.
다음으로는 이제 ToolBench로 Supervised Fine-Tuning한 ToolLLaMA를 통해 새로운 명령과 Tool에 대한 일반화 능력을 평가하였다.
먼저 LLaMA-2 7B 모델을 명령 - 해결 경로 쌍을 사용하여 fine-tuning 한다. 기본 LLaMA-2 모델의 시퀀스 길이는 4096이지만 API 응답은 매우 길 수 있기 때문에 이를 확장해야 한다. 이를 해결하기 위해 위치 보간법을 사용하여 컨텍스트 길이를 8192로 확장한다.
ToolLLaMA의 일반화 능력은 세 가지 수준에서 평가한다.
Inst. : 훈련 데이터에서 사용된 도구들이 동일하지만 새로운 명령을 처리하는 능력.
Tool : 훈련 데이터에 등장한 도구들과 동일한 카테고리에 속하는 새로운 도구를 처리하는 능력.
Cat. : 훈련 데이터에 등장하지 않은 다른 카테고리에 속하는 새로운 도구를 처리하는 능력.
ToolLLaMA의 성능을 평가하기 위해 세 가지 시나리오에서 실험을 진행한다.
- I1(단일 도구 명령) : 단일 도구에 대한 명령을 처리하는 시나리오. 이 시나리오에서는 위에서 설명한 세 가지 수준 모두에 대해 평가를 수행한다.
- I2(카테고리 내 다중 도구 명령) : 동일한 카테고리에 속하는 여러 도구를 사용하는 명령. 이 시나리오에서는 Inst.와 Cat.에 대한 일반화 능력만 평가한다. 이는 훈련 중에 이미 동일 카테고리 내에서 여러 도구를 사용하는 명령이 포함되어있기 때문이다.
- I3(컬렉션 내 다중 도구 명령) : 여러 카테고리에 속하는 도구들을 포함한 명령. 이 시나리오는 이미 다양한 도구 조합을 다루고 있으므로 Inst. 에 대한 일반화 능력만 평가한다.

위 표는 모델 별로 성능을 측정한 평가표이다. 이때 ReAct와 DFSDT 방식을 적용하면서 두 방식의 성능 차이도 확인하고 있다.
위 표에서 Vicuna와 Alpaca는 도구 사용 분야에서 어떤 명령도 수행하지 못했는데 이는 모델이 주로 언어 처리 능력에만 집중되어 있기 때문에 도구 사용 능력이 부족하다는 것을 나타낸다.
이외의 모델들에서는 DFSDT방식이 ReAct 방식보다 pass rate와 win rate 모두 더 높은 성능을 보였다.특히 ChatGPT + DFSDT가 GPT-4 + ReAct보다 pass rate가 더 높았으며 win rate도 비슷한 성능을 보여주었다. ToolLLaMA + DFSDT는 Text-Dacinci-003와 Claude-2보다 더 나은 성능을 보여주었으며 ChatGPT와 거의 비슷한 성과를 달성했다. 전반적으로 ToolLLaMA + DFSDT는 새로운 명령과 새로운 API에 대해 일반화 성능을 잘 보여주었으며 모든 시나리오에서 경쟁력 있는 성과를 나타냈다. 통과율에서는 GPT-4 + DFSDT 다음으로 가장 높은 결과를 기록했다.
[Conclusion]
ToolLLM은 LLM이 tool을 활용하는 방법을 학습하고 발전시킬 수 있는 방법을 소개한다. ToolBench 데이터셋을 생성하여 16,000개 이상의 실제 API와 다양한 실전 사용 사례 시나리오를 다룰 수 있도록 제공하였고 DFSDT를 제안하여 LLM의 계획 및 추론 능력을 강화하였다. 또한 도구 학습의 효율적인 평가를 위해 ToolEval을 개발하였다. ToolBench를 기반으로 LLaMA 모델을 fine-tuning하여 다양한 도구를 활용하는 모델인 ToolLLaMA 모델을 생성하였으며 이 모델은 ChatGPT와 유사한 성능을 보였다.
이 논문을 읽게 된 이유는 LLM을 활용하여 Time-series 데이터를 예측하는 분야에 대해 공부하던 중 Tool을 활용하여 LLM이 시계열 데이터를 예측하도록 하는 방법이 있다고 하여 보게 되었다. 이 논문은 LLM에게 어떤 특별한 작업을 통해 시계열 데이터에 특화되어 처리하는 것이라기 보다 LLM이 사용자의 요구사항에 따라 다양한 Tool 중에 사용자의 요구사항에 맞는 API를 조합하여 요구사항을 처리해주는 방법이다. 따라서 어떤 특정 도메인 시계열 데이터를 예측하는 것에 있어서 해당 API가 존재한다면 ToolLLaMA가 잘 조합하여 해결해주겠지만 관련 API가 존재하지 않는다면 LLM을 활용하여 시계열 데이터를 예측하는 것과는 거리가 먼 논문이라고 생각이 들었다.
실제로 RapidAPI에 시계열 데이터 예측 API가 얼마나 존재하는지 궁금하여 찾아보았다. 각 분야별로 시계열 데이터를 예측하는 API들이 존재하였다. 따라서 어떤 분야의 시계열 데이터를 예측하고 싶은지 요구사항을 ToolLLM에게 제공한다면 해당 API들을 잘 조합하여 예측할 것으로 생각된다.



