[Background]
LLM을 활용한 시계열 데이터 연구에 대한 Background 내용은 밑에 링크의 Background 부분을 참고하길 바랍니다.
https://myownproject.tistory.com/51
[Paper Review]Time-LLM: Time Series Forecasting By Reprogramming Large Language Models
[Background]● 왜 TS에는 LLM에 관한 연구가 많이 진행되지 않았는가? TS의 특징으로 인하여 Pre-training을 수행하는 것이 어렵다. TS 데이터로 Foundation 모델을 학습시킬 많은 양의 데이터를 구하기
myownproject.tistory.com
[Summary]
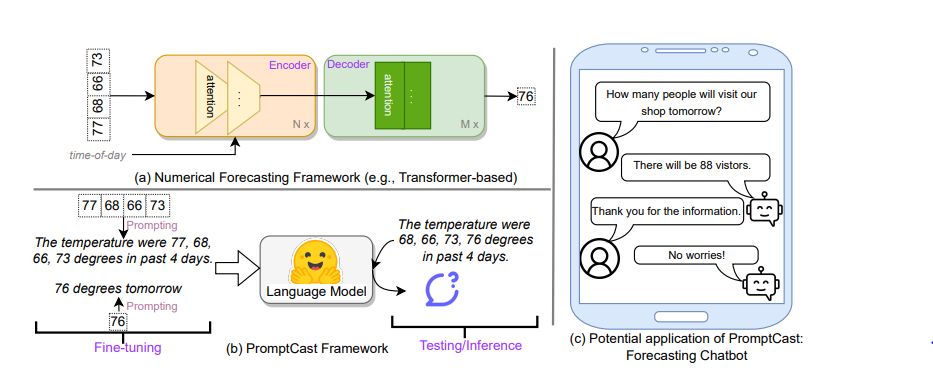
위 그림은 PromptCast 방식에 대한 구조이다.
PromptCast 방식은 사실 새로운 기술적 발전에 대한 논문이라기 보다 기존의 LLM을 시계열 데이터 예측에 사용할 수 있도록 LLM에 입력하는 형식을 정하여 입력하면 LLM이 시계열 예측을 하는데 있어서 높은 예측성공률을 보여준다는 연구이다.
● PISA
연구에 동일한 Template을 적용하기 위해 저자는 PISA라는 대규모 시계열 데이터셋을 제공한다. PISA는 세 개의 서로 다른 시계열 데이터셋을 통일된 형식으로 변환하여 결합한 데이터셋이다. 이 데이터셋은 각각 CT(City Temperature), ECL(Electricity Consumption Load), SG(SafeGraph Human Mobility Data)로 구성되어 있다. PISA를 구성하는 각각의 데이터셋에 대해 설명하겠다.
1. CT(City Temperature)
전 세계 110개 도시의 일일 평균 기온 데이터를 포함한다. 데이터는 2017년 1월1일부터 2020년 4월 30일까지 수집되었다. 주로 온도 예측에 사용되며, 관측된 기온 데이터는 섭씨가 아닌 화씨로 기록되었다.
2. ECL(Electricity Consumption Load)
원래 ECL 데이터는 총 321 사용자의 일일 전력 소비량 데이터를 포함하지만 PromptCast에서는 50명의 사용자를 랜덤으로 선정하였다. 데이터는 2012년 1월 1일부터 2014년 12월 31일까지 수집되었다. 각 사용자의 전력 소비 패턴을 예측하기 위해 사용되며, 기존에 누락된 값을 가진 사용자는 제외되었다.
3. SG(SafeGraph Human Mobility Data)
특정 지점을 방문한 사람들의 일일 방문자 수를 포함하는 데이터셋이다. 기존의 데이터셋에서 5개월치 데이터를 더 수집하여 구성하였다. 2020년 6월 15일부터 2021년 9월 5일까지 수집되었으며 324개의 특정 지점이 포함되었다. 인구 이동 예측을 위해 사용되며 SafeGraph의 주간 패턴 데이터를 기반으로 하고 있다.
● Template
LLM에 입력하는 기본적인 프롬프트 Template은 다음과 같다.
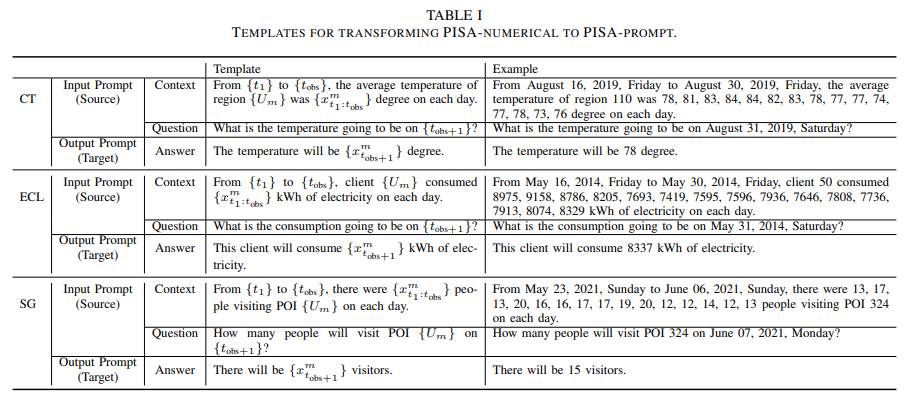
Input 시계열 데이터는 15개로 정해져있고 Output 시계열 데이터는 1개로 정해져있다. 각각의 데이터셋에 따라 예측할 때 주어진 Prompt Template을 따라 작성한다면 LLM이 Q&A 형식으로 출력하도록 하였다.
[Results]

위 표는 PISA numerical 데이터셋을 이용하여 수치 기반 시계열 예측을 수행한 여러 모델들의 성능 결과를 나타낸 것이다. 표에서 RMSE와 MAE는 모델의 성능을 측정하는 지표로 사용되었으며 세 가지 시계열 예측 과제에서의 성능을 평가하고 있다. 평가한 모델들로는 전통적인 모델부터 Transformer 기반 모델들까지 모두 평가하였다. 결과를 보면 비교적 최신 모델들인 Transformer 기반 모델들이 나머지들에 비해 더 나은 성능을 보여준다.

위 표는 PISA 데이터셋을 이용하여 다양한 LLM 모델들이 시계열 예측을 어떻게 수행했는지 성능 평가한 결과를 나타낸 것이다. 성능 평가 지표는 RMSE와 MAE의 평균과 표준편차로 선정하여 평가하였으며 세 가지 데이터셋(CT, ECL, SG)에 대해 평가하였다. 사용한 LLM모델들이 가장 최신의 모델이 아닌 것이 아쉽지만 그래도 수치 기반 모델들과 비교했을 때 비슷하거나 더 좋은 성능을 보인걸로 보아 시계열 예측 분야에 LLM을 사용하는 것이 하나의 방법이 될 수 있다는 가능성을 보여주었다.
[Conclusion]
이 논문에서 얘기하고자 하는 바는 PromptCast 방식으로 LLM을 사용하여 시계열 예측을 할 수 있다는 것이다. LLM은 프롬프트로 제공된 시계열 데이터를 이해하고 사용자의 요구에 맞게 응답할 수 있다고 주장하며 수치기반 예측 모델들과 비교해도 경쟁력 있는 성능을 발휘할 수 있음을 보여주었다. PromptCast는 LLM을 시계열 예측에 효과적으로 사용할 수 있는 방법을 제시했으며, 프롬프트 설계가 모델 성능에 중요한 역할을 한다는 것을 강조한다.
이 논문은 현재 One fits all 논문과 함께 LLM for Time series 분야의 초석이 되는 논문이다. LLM으로 시계열 예측을 한다는 발상을 했다는 점에서 이 논문이 의미하는 바가 크다고 생각한다.
논문을 읽으면서 몇 가지 아쉬웠던 부분이 있었다. 먼저, 이 논문은 LLM을 시계열 예측에 활용하기 위해 제시한 프롬프트를 사용하면 더 좋은 성능을 낸다고 주장하는 논문이다. 어떻게 보면 ChatGPT에게 이런 형식으로 질문을 한다면 좋은 성능을 보여준다고 하는 것과 같은 논문인 셈이다. 또한 이 논문에서는 정해진 Template이 input window = 15이고 output =1이었기에 실험 결과가 유의미한 것인지에 대해 의문이 든다. 또한 논문에서 LLM에 해당 프롬프트를 적용하여 입력값을 제공했을 때 왜 예측을 잘 했는지, 어떤 기술적인 부분이라던가 좀더 다양한 방식의 프롬프트를 적용하여 비교했다면 좀 더 좋은 연구가 되지 않았을까 생각한다.
[Reference]
Hao, Flora "PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting" arXiv:2210.08964v5(2023)



