[Background]
● TEST 논문에서 LLM을 활용하여 Time Series 데이터를 예측하는 방법을 크게 두 가지로 분류한다.
1. LLM-for-TS : Time-Series data를 잘 처리하도록 LLM을 fine-tuning 하는 것이다. 또는 존재하는 pre-trained LLM을 fine-tuning하여 text 기반 작업에서 Time-Series 기반 작업으로 변환한다.
2. TS-for-LLM : 존재하는 LLM을 기반으로 LLM을 freeze 한 후 LLM이 Time-Series 데이터를 잘 처리하도록 LLM 친화적으로 Time-series 데이터를 처리하는 메커니즘을 설계한다.
사실 LLM이 TS data에 잘 반응하도록 LLM 모델을 설계하고 학습시키는 것이 이 연구를 끝낼 수 있는 가장 근본적인 해결책이다. 두 번째 방법은 실제로 모델의 원래 기능을 넘어서는 것이 어렵다. 하지만 현재 몇 가지 고려사항으로 인해 두 번째 방법에 연구가 집중되고 있다.
데이터의 관점에서 볼 때, 첫 번째 방법은 기초 모델을 구성할 때 대규모의 데이터셋이 필요하지만 시계열의 가장 큰 데이터셋의 경우 10GB 미만이다. 하지만 두 번째 방법을 사용하면 기존 LLM의 시계열 예측을 지원하는 것이 목적이므로 상대적으로 작은 데이터셋을 사용할 수 있다.
모델의 관점에서 볼 때, 첫 번째 방법은 수직 산업에 중점을 둔다. 도메인 간의 데이터셋의 차이점 때문에 다양한 대형 모델을 처음부터 구축하고 훈련해야 한다. 하지만 두 번째 방법은 훈련이 거의 또는 전혀 필요하지 않다.
사용의 관점에서 볼 때, 첫 번째 방법은 전문가의 경우에 적합하지만 두 번째 방법은 LLM의 텍스트 기능을 유지하며, 접근하기 쉽고 사용자 친화적인 방법이다.
[Summary]
TEST는 TS Token Augmentation & Encoding, Instance-wise & Feature-wise Contrast Learning, Text-Prototype-Aligned Contrast, Learnable Prompt Embedding으로 나눠 볼 수 있다.
▶ TS Token Augmentation & Encoding
이 단계에서는 간단히 말하면 시계열 데이터를 전처리하는 과정이다. 먼저 시계열 데이터를 k개의 타임 윈도우로 나눈다. 그리고 하나의 기준 데이터를 정하여 Anchor로 설정하고 이 기준 데이터에 증강하거나 변형하여 Positive와 Negative 데이터를 설정한다. Positive는 s(원본 시계열 데이터 구간)를 Anchor 인스턴스라고 할 때, jitter와 scaling을 적용한 s를 weak로, jitter와 permutation을 적용한 s를 strong으로 설정한다. s-weak는 원본 데이터와 더 유사한 변형이고 s-strong은 원본 데이터와 좀 더 다른 변형이다. s-weak와 s-strong을 Positive로 설정하고 나머지 다른 데이터들은 Negative로 설정한다. 이 과정을 AutoEncoding을 통해 임베딩한 후 Linear 레이어로 Projection 한다. AutoEncoding 과정에 대해 좀더 설명하자면 AutoEncoder는 복원 손실로 훈련되고 Decoder는 훈련 시에만 사용하고 테스트 및 추론 단계에서는 사용되지 않는다. 또한 후속 훈련 과정을 AutoEncoder가 직접 하는 것이 아니라 별도의 Linear 레이어를 통해 수행하여 AutoEncoder의 임베딩 공간이 붕괴되는 위험을 회피한다.
※ 공간 붕괴(Dimension Collapse)란?
공간 내에서 다른 의미를 가진 데이터들이 서로 유사하거나 동일한 데이터로 인식되는 상황을 공간 붕괴라고 한다. 공간 붕괴는 대조학습의 경우에 손실함수의 잘못된 설정으로 인해 모델이 데이터를 충분히 구분하지 못할 수 있을 경우에 발생할 수 있다. 따라서 해당 학습에서는 AutoEncoding을 통해 임베딩한 후 Linear 레이어로 Projection하는 과정을 통해 공간 붕괴를 회피하고자 한다.
이 후 전처리한 데이터로 Instance-wise Contrast Learning과 Feature-wise Contrast Learning을 수행한다.
▶ Instance-wise & Feature-wise Contrast Learning
1. Instance-wise Contrast Leaning
Anchor 인스턴스가 Positive 와는 가깝도록하고 같은 배치 내의 Negative와는 멀도록 훈련한다.
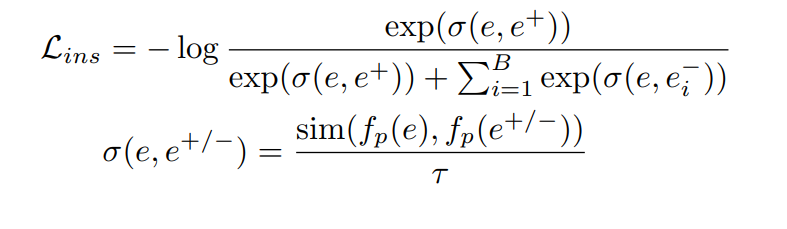
Instance-wise Contrast Learning Loss Function은 위와 같다. 먼저 인스턴스 임베딩 e와 $e^{+/-}$가 주어졌을 때, $f_{p}$ 라는 하나의 층으로 이루어진 다층 퍼셉트론(MLP)을 통해 $f_{p}(e)$라는 변환된 벡터를 얻는다. $\sigma (e,e^{+/-})$는 두 투영된 벡터 간의 유사성을 계산하는 데 사용된다. 즉, 원본 벡터 e와 Positive 또는 Negative 벡터 간의 유사성을 계산한다. 유사성 계산에는 코사인 유사도(cosine similarity)와 같은 유사도 함수를 사용하여 이뤄지며, 인스턴스 수준에서의 온도 매개변수($\tau$)가 적용된다. 이 온도 매개변수는 유사도 값을 조정하여 학습을 더 안정적이고 효과적으로 만들 수 있다.
※ 온도 매개변수($\tau$)
주로 대조학습이나 분류 모델의 소프트맥스 함수에서 사용되며 유사도 값을 조정하여 모델의 학습 과정에서 출력값의 분포를 더 민감하게 또는 덜 민감하게 만드는 역할을 한다.
2. Feature-wise Contrast Learning
특징 열을 기준으로 Positive와 Negative 데이터를 비교하여 유사성 또는 차이점을 학습하는 방식이다.
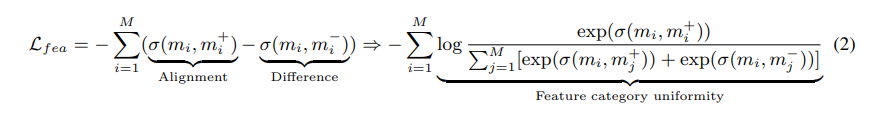
Feature-wise Contrast Learning Loss Function은 위와 같다. 먼저 Anchor 특징 행렬 m에 대해 알아보자. m은 B-th row copy of the vector e로 주어진 Anchor 특징 행렬이다. 즉, 벡터 e의 여러 복사본이 행렬 m의 행에 배치된 구조이다. 그러면 m의 각 열은 각 특징점을 나타내게 된다. Positive와 Negative 특징 행렬 또한 마찬가지로 벡터 e의 여러 복사본을 포함한다. m+/-는 B개의 벡터 e로 이루어진 Positive 및 Negative 특징 행렬이다. 이제 m 특징 행렬과 m+/- 특징 행렬에 대해 각 열이 Positive 특징 행렬과 m 특징행렬은 가깝게, Negative 특징 행렬과는 멀어지도록 훈련한다.
이렇게 같은 열만 비교하는 방식은 공간 붕괴를 초래할 수 있다. 특징 간의 차이를 충분히 학습하지 못하고, 모델이 모든 데이터를 좁은 공간에 배치하게 되어 임베딩 공간이 축소될 수 있다. 이러한 방법을 해결하기 위해 다른 특징 열 간의 대조도 학습에 포함시킨다. Positive와 Negative 간의 같은 열을 비교하는 것뿐만 아니라, 다른 열 간의 차이도 비교하여 학습을 더 정교하게 만든다. 위 Loss Function의 우측 화살표 이후에 나온 항목이 특징 열 간의 차이를 강조하여 공간 붕괴 문제를 해결하기 위한 개선 방법을 나타낸 것이다.

▶ Text-prototype-aligned Contrast Learning
이제 시계열 데이터를 LLM의 Text token embedding에 매핑하는 방법에 대해 알아보자. LLM은 입력된 텍스트를 고차원 임베딩 벡터로 변환하는 임베딩 공간을 가지고 있다. 이제 시계열 데이터를 LLM에 입력하려면 LLM이 입력으로 들어온 시계열 데이터를 인식할 수 있도록 시계열 데이터가 임베딩 공간에 위치해 있어야한다. 하지만 시계열 데이터는 텍스트 토큰과 달리 직접적인 텍스트 주석이 없는 값이다. 이를 해결하기 위해 TEST에서는 시계열 데이터 토큰을 LLM의 텍스트 임베딩 공간에 매핑하려고 시도한다. 이를 위해 유사성 추정을 사용하여 시계열 데이터의 임베딩 벡터를 텍스트의 값, 모양, 빈도와 같은 일반적인 설명과 가깝게 배치한다. 시계열 데이터는 LLM이 이해할 수 있는 텍스트 데이터로 직접적으로 변환되지 않지만 텍스트 임베딩 공간에 매핑하여 시계열 데이터를 텍스트 토큰의 패턴처럼 학습할 수 있다. 예를 들어, 시계열 데이터에서 상승하는 패턴은 텍스트 토큰 'up', 하락하는 패턴은 'down'과 같은 텍스트 토큰 근처에 배치시킨다. 이를 통해 LLM이 시계열 데이터에서 패턴을 인식할 수 있도록 돕늗다.
TEST 기법에서는 P개의 대표적인 텍스트 임베딩을 기준점으로 설정한다.(Text-Prototype) 각 프로토타입은 특정 패턴을 나타낼 수 있으며, 시계열 데이터를 이 프로토타입에 매핑한다. 이 매핑하는 과정에서 Contrast Learning이 적용된다.(유사한 시계열 데이터 패턴은 비슷한 텍스트 좌표축으로, 유사하지 않은 것은 먼 쪽으로 매핑된다.) 프로토타입의 개수가 많을 수록 시계열 데이터의 다양한 패턴을 각각의 차원으로 표현할 수 있다. 이제 시계열 데이터 임베딩 공간과 텍스트 임베딩 공간이 서로 비슷한 범위를 가지도록 만들기 위해 정렬한다. 정렬을 통해 두 공간이 일치하도록 제약을 설정하고, 시계열 데이터가 텍스트 프로토타입 공간에 올바르게 배치될 수 있게 돕는다. 또한 대조 항목은 텍스트 프로토타입을 좌표처럼 사용하여 시계열 데이터를 이 텍스트 좌표축에 맞춰 배치한다. 텍스트 프로토타입을 기준으로 시계열 데이터의 패턴을 표현하는 것이며, 유사한 시계열 데이터는 비슷한 프로토타입 좌표에 배치되도록 학습된다.
만약 입력으로 들어오는 시계열 데이터가 텍스트 프로토타입에 존재한다면, 우리는 굳이 인코더를 통해 시계열 데이터를 Positive, Anchor, Negative로 분류하고 대조학습을 수행하는 과정을 생략해도 된다. 왜? 이미 수행한 것이기 때문이다. 텍스트 프로토타입에 입력되어있는 시계열 데이터라면 이를 기준으로 시계열 데이터의 특징 행렬을 얻어, 이를 대조 학습 및 LLM 처리 과정에 활용할 수 있기 때문이다. (물론 기존의 텍스트 프로토타입에 없는 새로운 시계열 데이터가 입력되면 당연히 기존의 과정을 따라야 한다.)

이 식은 시계열 데이터와 텍스트 임베딩을 정렬하고 대조 학습을 적용하는 손실 함수를 나타낸다. 여기서는 두 가지 주요 과정인 텍스트 정렬과 텍스트 대조 과정을 포함하고 있다.
먼저 텍스트 정렬 과정은 텍스트 프로토타입과 시계열 데이터의 임베딩 벡터간의 유사성을 계산하여 두 데이터가 얼마나 비슷하게 임베딩되었는지를 측정하여 텍스트와 시계열 데이터 간의 정렬을 수행한다.
텍스트 대조 과정은 대조 학습을 적용한 손실 항목이다. 시계열 데이터의 특징 행렬 e, Positive e, Negative e 각각 텍스트 프로토타입과의 차이를 학습한다.
이 손실값으로 최대한 텍스트 프로토타입과 시계열 데이터 임베딩이 유사하도록 학습하여, 시계열 데이터가 텍스트 기반 패턴을 따르게 한다. 또한 대조 학습을 통해 시계열 데이터 간의 차이를 구별한다. Positive와 Negative 데이터를 비교하여 시계열 데이터가 어떻게 다른 패턴을 가지는지 학습한다.
▶ Learnable Prompt Embedding
이제 LLM이 시계열 데이터를 잘 처리할 수 있도록 프롬프트도 튜닝해줘야 한다. TEST 기법에서는 소프트 프롬프트를 사용한다. 소프트 프롬프트는 LLM에서 프롬프트가 주어졌을 때 이를 통해 특정 태스크에 맞춰 시계열 데이터를 처리하는 방식이다. 프롬프트에 관한 Supervised Fine-Tuning 내용은 GPT4TS 논문을 참고하길 바란다.


위 두 수식에서 먼저 첫 번째 수식은 파라미터$\phi$를 조정하여 조건부 확률을 최대화하려는 목적이다. 해당 조건부 확률은 어떤 입력 x에 대해 최적의 출력을 내놓을 수 있도록 파라미터를 최적화하는 과정을 설명한다. 이때, h는 두 번째 수식으로 적용된다. h는 프롬프트가 특정 위치에서 주어졌을 때, 해당 프롬프트에 맞춰 시계열 데이터를 처리하고, 그렇지 않을 경우에는 일반적인 LLM 방식으로 작동하도록 설계되었다.
[Results]

a~d는 Classification 작업을 수행한 결과이고 e~h는 forecasting 작업을 수행한 결과, i는 SVM(Support Vector Machine)을 사용하여 TEST 기법으로 생성된 시계열 임베딩의 분류 성능을 평가한 결과이다. i의 결과는 표현 학습을 설명하였는데 시계열 데이터이 어떻게 LLM의 임베딩 공간에 맞춰 표현되는지에 대해 논의하고 매칭하는 과정을 보여주었다. 또한 그림의 빨간 점선은 가장 좋은 결과를 나타낸다.
TEST 기법은 나머지 작업에서는 다른 모델들보다 조금 나은 성능을 보이지만 일반적인 forecasting과 few-shot forecasting에서 확연히 좋은 성능을 보였다.

이 그림은 최근접 이웃 방식를 사용하여 시계열 데이터가 텍스트 임베딩에 나타내는 단어를 나타낸 것이다. 이때, 프롬프트를 통해 LLM이 시계열 데이터를 감정 분류 작업처럼 처리할 수 있도록 유도한다. 결과를 보면, 실제로 매칭된 단어가 감정과 관련된 단어였다. 시계열 데이터의 특정 패턴이 Active 또는 silent와 같은 감정을 표현하는 단어와 매칭된다는 것을 보여준다. 이를 통해 LLM이 시계열 데이터를 단순한 숫자 시퀀스가 아니라 패턴으로 인식하며, 이를 통해 시계열 데이터에서 패턴을 식별한다는 것을 알 수 있다.
이러한 결과로 논문에서는 숫자 시퀀스로 시계열 데이터를 단순히 처리하는 것 대신, 단어를 사용하여 시계열 데이터에서 패턴을 식별하는 것을 제안한다. 특히 SFT(Soft Fine-Tuning)이 없는 LLM은 수학적 작업에 적합하지 않지만 패턴을 추출하는 작업에는 뛰어난 성능을 발휘한다.
[Conclusion]
이러한 실험 결과를 통해 본 논문은 TEST 기법이 시계열 데이터 임베딩 방법을 제시하였으며, 이를 통해 LLM의 역량을 확장하고, 패턴 인식 능력을 활용하여 TS-for-LLM을 처리할 수 있도록 하였다고 설명한다. 더 나아가 LLM의 크기, 프롬프트, 데이터셋의 영향도 성능에 중요한 역할을 하며, 앞으로 코퍼스와 시계열 데이터 간의 관계에 대한 추가 연구가 필요하다고 강조하며 마무리 한다.
본 논문을 읽으면서 대조학습을 통해 시계열 데이터를 B차원의 임베딩 공간에 매핑하여 텍스트 임베딩 공간처럼 다루어 텍스트 임베딩 공간에 매핑하려는 시도는 새로운 경험이었다. 어쩌면 시계열 데이터를 위한 LLM을 설계하고 개발한다면 이런 개념이 사용되진 않을까 생각도 들었다. 하지만 반대로 이런 생각도 들었다. 시계열 데이터를 텍스트 임베딩 공간에 매핑하려면 오류 없이 작동하기 위해서는 거의 모든 시계열 데이터의 패턴이 입력되어야 한다. 하지만 시간에 따라 생성되는 시계열 데이터는 셀수 없이 많은 패턴이 생성될 수 있는 가능성이 존재한다. 본 논문에서 제시한 LLaMa2, ChatGLM의 임베딩 차원의 개수는 4096개이다. 내 생각이지만 이 정도의 차원으로는 모든 시계열 데이터를 분류하기 위해서는 시간에 따라 시계열 데이터를 분류하는 단위가 커야 가능할 것이라고 생각한다.
아쉬운 점은 사실 대조학습에 관한 부분이 이 논문의 핵심 부분이라고 생각했는데 읽다보니 어쩌면 프롬프트를 설계하는 방법이 더 중요할 것 같다는 생각이 들었다. 최근접이웃 알고리즘을 활용하여 시계열 데이터를 LLM의 감정을 표현하는 단어로 매핑하도록 프롬프트를 작성하여 LLM에게 제공한다. 그렇다면 만약 프롬프트 없이 LLM에게 해당 데이터를 제공한다면 시계열 데이터를 분류하는 기준점(차원)의 개수가 훨씬 많아져 표현할 수 있는 방법이 더 많아지지 않을까 생각이 들었다. 각각의 시계열 데이터가 나타내는 단어들을 매핑하여 역으로 출력할 수 있다면 복잡하지만 더 정확한 예측을 수행할 수 있지 않을까 싶었다.



