[Background]
● 왜 TS에는 LLM에 관한 연구가 많이 진행되지 않았는가?
TS의 특징으로 인하여 Pre-training을 수행하는 것이 어렵다. TS 데이터로 Foundation 모델을 학습시킬 많은 양의 데이터를 구하기 어렵다. 현재 TS analysis를 위한 가장 큰 데이터셋은 10GB미만이다.
각 데이터셋의 특징 및 구조가 달라 이를 합쳐 대규모의 Pre-training dataset 구성이 어렵다. 각각의 dataset의 Instance, Feature, Granularity 등에서 차이가 존재한다. 또한, Domain마다 dataset마다 통계적인 특성이나 Scale 등에서 차이가 존재한다.
● Transformer 모델의 성공
Transformer 모델이 처음 제안된 이후 자연어 처리 분야에서 큰 성공을 거두었다. 특히 언어의 복잡한 관계나 장기적인 의존성을 효과적으로 학습할 수 있었다. 이러한 성공을 기반으로 이를 다른 형태의 데이터를 처리하는 것에도 사용할 수 있지 않을까 하며 LLM으로 TS data를 처리하는 연구가 시작되었다.
● TS 데이터를 예측하는 데에 LLM을 사용하는 이점
TS 데이터와 Natural Language는 모두 시간 또는 순서에 따라 의미가 변화하는 Sequential한 구조를 가지고 있다. 이때, 모델이 Natural Language 데이터 간의 관계를 잘 구분할 수 있도록 학습했다면 TS data가 Input으로 주어졌을 때에도 TS data를 Natural Language로 처리하는 Modality align 과정이 있다면 시간 순서에 따른 패턴을 잘 파악할 수 있다.
TS 데이터를 Numerical digits의 string 형태로 다룬다면 TS forecasting을 Next-token prediction처럼 간주할 수 있다.
● 기존 TS 데이터 처리의 문제점
기존의 TS forecasting 모델은 RNN, LSTM, GRU 같은 순환 신경망을 사용한다. 하지만 이 모델들은 시간이 지남에 따라 발생하는 데이터의 장기 의존성을 학습하는 데 한계를 보였다. 특히 긴 시계열에서 정ㅇ보가 소실되거나 기울기 소실 문제가 발생하는 문제가 있다. 하지만 Transformer 모델은 모든 시간 단계에서 Self-Attention을 사용하여 과거의 모든 Time-step 정보를 동일하게 다룰 수 있기 때문에 문제를 해결할 수 있다.
● 관련 연구 동향

[Summary]
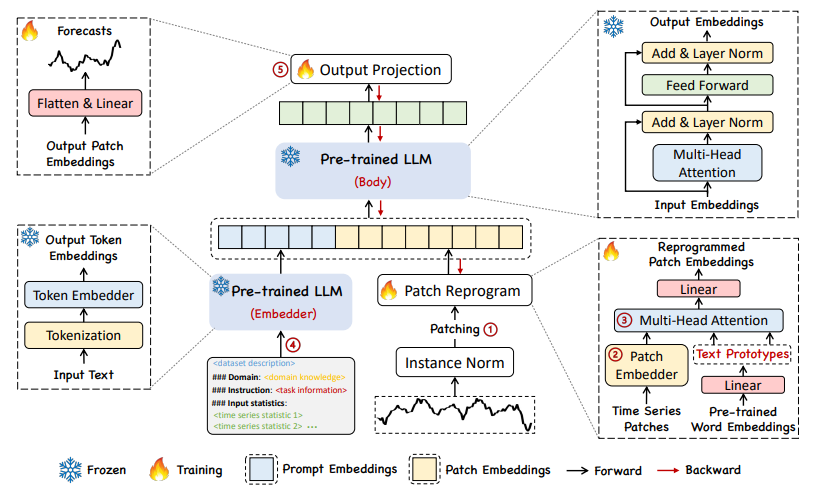
Time-LLM 논문에서 제시하는 TS data를 처리하는 구조는 다음과 같다. TS data는 먼저 Instance Norm, Patching, Patch Reprogram, Pre-trained LLM(Body), Output Projection 순으로 처리된다.
순서대로 설명해보자면
먼저 TS data가 입력으로 주어진다. 그러면 이 TS data에 대해 정규화 과정을 거친다. 논문에서 제시한 정규화 방식은 RevIN이다. TS data는 non-stationary하기 때문에 TS forecasting model이 domain shift 문제를 겪을 수 있기에 이 방식을 사용하였다.
※ RevIN 정규화 방식(Reversible Instance Normalization)이란?

입력 TS data를 기반으로 평균과 분산을 계산하고, 이 파라미터를 감마와 베타라는 학습 가능한 파라미터와 결합하여 아핀 변환을 하여 데이터를 정규화한다. 그 후 모델에 데이터를 입력하고서 나온 출력값을 다시 비정규화하여 TS forecasting을 수행하는 방식이다.
Patching
이제 TS data를 패치 단위로 쪼갠다. TS data를 패치로 분할하게 되면 Sequence의 dimention을 조절할 수 있고 로컬 정보를 잘 포착할 수 있다. 물론 당연하겠지만 패치를 어떻게 설정하느냐에 따라 복잡도가 달라진다.
Patch Reprogramming
Patching된 시계열 데이터를 이용하여 LLM이 이해할 수 있는 형태의 데이터로 변환하는 단계이다. 이를 위해서 Time-LLM에서는 Text prototypes 개념을 도입한다.
※ Text Prototypes

위 그림의 Source 부분에서 Vocab. 부분의 단어 집합을 Word2vec 방식을 통해 임베딩한 후, 이를 선형 결합하여 새로운 벡터 E`을 생성한다. E`<<E이다.
E`부분의 파란색 노드는 early와 down이 결합하여 "early down"의 의미가 가질 것이고, 빨간색 노드는 steady와 long이 결합하여 "steady long"의 의미를 가질 것이다. 이 두 벡터는 Attention(여기서는 patch로 들어온 시계열 데이터와 Prototypes 간의 Cross Multi head attention)을 통해 처음에는 줄어드는 모양이었다가 데이터가 안정적으로 변화하는 구간이 길게 지속된다는 의미를 나타내게 될 것이다. 그러면 파란색 노드와 빨간색 노드가 결합하는 TS Patch 1은 방금 언급한 형태의 TS data를 Text 형태로 나타낼 수 있다.
이런 방식으로 TS data를 reprogramming하면 언어로 학습된 LLM이 TS data를 잘 이해할 수 있다. Patch reprogramming 과정 중 Cross multi-head attention에서 Query matrices는 Patch embedding 벡터로 생성하고, Key와 Value matrices는 Text Prototypes로 생성한다. 수식적인 부분은 다음과 같다.

다음은 Attention 값들을 각 head에서 계산한 후, 이를 결합하고, 최종적으로 선형 변환을 통해 Backbone 모델의 hidden dimension에 맞게 정렬한다. 여러 헤드에서 얻은 정보를 결합하고, Backbone 모델이 처리할 수 있는 형식으로 변환하는 단계이다.
여기까지가 Patch Reprogramming 과정이다.
이제 LLM 모델에 대해 살펴보자.
TS data를 단순히 reprogramming하는 것으로 LLM의 추론 능력을 극대화하는 것을 기대하기에는 어렵다. 따라서 LLM의 추론 능력을 높여주기 위해 입력 TS data에 대한 정보를 보충해준다.
※ Prompt-as-Prefix(PaP)
LLM에게 정보를 보충하고자 할 때에는 형식이 있는 템플릿 형태로 제공한다. Data context, Task instruction, Statistics 부분으로 나누어 제공한다.

▶ Data context : LLM에게 현재 주어진 dataset에 대한 배경 지식을 전달한다. 이 부분은 모델에 입력되는 데이터의 종류나 형태, 데이터의 구간, 기본적인 패턴 등을 나타내며 LLM이 어떤 데이터를 처리하고 있는지 이해할 수 있도록 한다.(그림에서 BEGIN DATA 이전 부분까지)
▶ Task instruction : LLM에게 우리가 하고자 하는 task가 무엇인지 전달한다. 예를 들어, 모델이 미래의 TS 값을 forecasting할지, 데이터 분류나 변화 탐지 등의 작업을 수행할 지를 명시한다.(그림에서 BEGIN DATA부터 Statistics 이전까지)
▶ Statistics - LLM에게 TS의 통계적 특성을 나타내며, 모델이 데이터를 더 깊이 이해하고 처리할 수 있도록 추가적인 정qh를 제공한다. 통계 정보로는 평균, 표준편차, 최대값, 최소값, 분산 등 통계적 지표를 포함할 수 있다. 이 정보들은 데이터의 패턴을 더 명확하게 인식하는 데 도움이 되며, 특히 LLM이 TS data의 변화 패턴을 예측하는데 유용하다.(그림에서 Statistics 부분)
PaP 정보와 Patch reprogramming 정보를 결합하여 LLM에 input하고 LLM은 text형태의 데이터로 예측값을 도출한다. LLM이 예측한 값(Output Embedding)을 평탄화하고, 평탄화된 값을 선형 변환을 통해 다시 TS data 형태로 복원한다.
여기까지가 Time-LLM이 제안하는 LLM으로 TS data를 예측하는 방법에 대한 내용이다.
[Results]
Time-LLM은 여러 벤치마크와 설정, 특히 few-shot, zero-shot 시나리오에서 최첨단 예측 방법을 지속적으로 큰 폭으로 능가했다. Time-LLM의 성능평가를 위해 최근 연구를 포함한 광범위한 최신 모델들과 비교하였다. 또한 비교에서 Long-Term Forecasting과 Short-Term Forecasting을 나누어 각각의 dataset과 평가지표를 설정하여 평가하였다.
1. Long-Term Forecasting
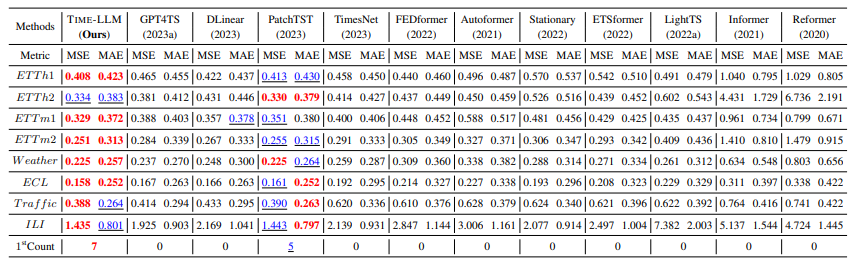
Long-Term Forecasting은 dataset을 장기 예측 모델 벤치마킹에 광범위하게 채택된 ETTh1, ETTh2, ETTm1, ETTm2, Weather, Electricity (ECL), Traffic, 그리고 ILI에 대해 평가한다. 입력 TS의 길이(T)는 512로, 서로 다른 예측 지평선은 H ∈ {96, 192, 336, 720}, 평가지표로는 평균제곱오차(MSE)와 평균절대오차(MAE)를 사용하여 4개의 TimeLine에 대해 평균을 내어 나타냈다. ILI의 경우 H ∈ {24, 36, 48, 60}을 사용했다.(아마 ILI 데이터의 특성 때문일 것 같다.) 당연하게도 오차를 평가지표로 사용했기에 값이 작을수록 좋은 모델이다.
결과는 대부분의 최신 첨단 모델들과 비교해보았을 때 의미있는 퍼포먼스를 보였다. 특히 GPT4TS와의 차이에 의미를 크게 두었으며 GPT4TS와는 12%의 차이를, Timesnet과는 20%의 평균 성능 향상을 보였다.
2. Short-Term Forecasting
Short-Term Forecasting은 dataset을 다양한 sampling 주파수의 마케팅 데이터 컬렉션이 포함된 테스트베드로 M4 벤치마크를 선택한다. 이 경우 예측 지평선은 상대적으로 작고 [6,48]에 있다. 입력 길이는 예측 지평선의 두배이며 평가 지표는 대칭 평균 절대 백분율 오차(SMAPE)와 평균 절대 척도 오차(MSAE) 및 전체 가중 평균(OWA)로 진행하였다.
결과는 다른 모델에 비해 좋은 성능을 보였다.

3. Few-Shot Forecasting
Few-Shot Forecasting의 setup은 Long-Term Forecasting과 동일하다.
[Few-Shot learning on 10% training data]

역시나 다른 모델에 비해 좋은 성능을 보여준다.
[Few-Shot learning on 5% training data]
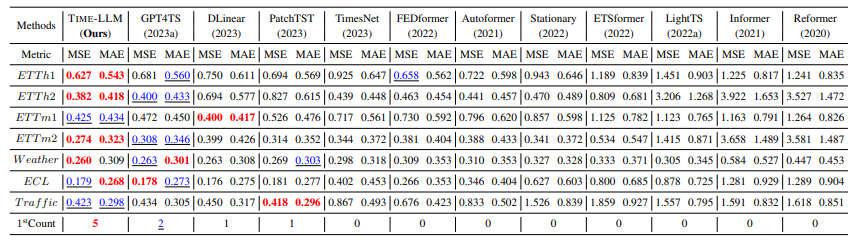
Few-Shot learning on 10%일 때보다 조금 성능이 떨어지지만 그래도 여전히 좋은 성능을 보여준다.
4. Zero-Shot Forecasting

5. Model Analysis
이번엔 (A) 각각의 LLM 모델에 대해 성능을 평가하고 (B) Patch Reprogramming이나 Prompt-as-Prefix 기능 없이 예측한 성능과 (C) Prompt-as-Prefix 단계의 각각의 부분 없이 성능을 평가한 결과이다.
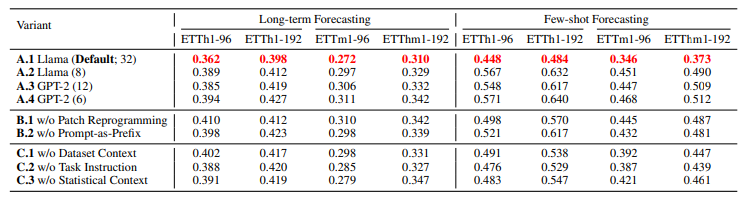
(A)의 괄호 안의 숫자는 transformer layer 수이다.
다음은 Backbone LLM을 사용할 때와 사용하지 않을 때의 효율성 비교이다.

LLM을 사용하지 않는 경우에는 속도가 확연히 떨어진 걸 알 수 있다. (예측 성공률도 상당히 떨어질 것으로 예상된다.)
마지막으로 전력 변압기 온도 dataset 중 하나인 ETTh1에 대해 case study를 진행한 결과이다. 저자들은 Reprogramming의 과정이 어떻게 진행되는지를 알아보고자 하였다. 100개의 Text Prototype과 48개의 TS patch를 이용하여 히트맵을 학습이 진행됨에 따라 시각화하여 나타냈다.

그림 (e) 부분에서 특히 높은 가중치를 보이는 부분이 있는데 이는 Text Prototype의 다양한 조합을 통해 서로 다른 특징을 갖는다는 것을 증명한다. 이를 통해 Text Prototype은 TS data를 Text 형태로 요약하는 방법을 학습하고 TS Patch의 정보를 표현하는 데 관련성이 높다는 것을 입증했다. 그림의 (f)부분에서는 언어 신호 중 일부는 TS Patch를 나타내는 데 특히 유용하며 이 유용한 신호를 Text Prototype이 학습하게 된다는 것을 증명했다.
[Conclusion]
위 연구를 통해 TS data를 Reprogramming하여 동결된 LLM으로 TS forecasting이 가능하다는 것을 보여주었다. TS data를 Reprogramming하는 방법과 Prompt-as-Prefix 방법을 통해 굳이 TS data에 특화된 foundation model을 생성하지 않고도 전문가 수준의 예측이 가능하다는 것에 큰 의의가 있다고 생각한다.
위 논문을 읽으면서 정말 깔끔한 방법이라는 생각을 했다. 현재 LLM은 NLP 및 CV 분야에서 큰 영향을 끼친 기술 중 하나이다. 어쩌면 스마트폰 이후의 세계를 바꿀만한 기술이라고 생각한다. 이러한 LLM의 변모성은 앞으로 사회에 큰 영향을 줄 것이라고 생각한다. LLM으로 TS data를 처리하는 다양한 방법이 존재하지만 범용성이 좋은 LLM을 굳이 변경하지 않고 TS data를 LLM이 이해하기 쉽게 처리하여 사용한다는 개념이 정말 좋은 아이디어라고 읽는 내내 생각했다. 더 좋은 Backbone 모델이 나오기 전까지 이 방법이 LLM으로 TS data를 예측하는 방법으로 사용되지 않을까 생각한다.
[Reference]
Jin, Ming, et al. "Time-llm: Time series forecasting by reprogramming large language models." arXiv preprint arXiv:2310.01728 (2023).
Taesung Kim, Jinhee Kim, et al. "Reversible Instance Normalization for Accurate Time-Series Forecasting against Distribution Shift" ICLR(2022).



