[Paper Review] DeepSeek-R1 : Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[Background]
● 강화학습(Reinforcement Learning, RL)
에이전트(Agent)가 환경(Environment)과 상호작용하여 보상(Reward)을 최대화하는 행동(Action)을 학습하는 방법으로 마르코프 결정 과정(Markov Decision Process, MDP)을 기반으로 작동한다.
MDP
- Agent : 행동을 수행하는 주체(Ex. LLM)
- Environment : 에이전트가 상호작용하는 대상(Ex. 텍스트 생성, 게임 환경)
- State : 현재 환경의 상태(Ex. 모델이 생성한 답변)
- Action : 에이전트가 수행하는 행동(Ex. 다음 토큰 예측)
- Reward : 특정 행동을 수행한 후 받는 점수(Ex. 답변의 논리성 평가)
- Policy : 최적의 행동을 결정하는 전략
강화 학습을 사용할 때는 주로 critic 모델을 사용하여 현재 행동이 얼마나 좋은지 평가한다. 기존 llm 모델에서 사용한 critic 모델은 하나의 답변에 대해 보상을 주어지고 피드백을 받아 최적의 행동을 선택하도록 학습한다면 본 논문에서는 critic 모델을 사용하지 않고 GRPO (Group Relative Policy Optimization) 를 사용하여 critic 모델에 비해 효율적으로 강화학습을 수행하였다고 한다. GRPO에 대한 자세한 설명은 [Summary]를 참고.
● 지식 증류
지식 증류(Knowledge Distillation, KD)는 큰 모델(Teacher Model)이 가진 지식을 작은 모델(Student Model)에 압축하여 전달하는 기법이다. 큰 모델에서 얻은 좋은 학습 결과를 더 작은 모델이 최대한 비슷한 성능을 재현하도록 하는 방법이다.
지식 증류 방법
- 소프트 타겟 증류(Soft Target Distillation)
Hard Target vs Soft Target : Hard Target은 정답 레이블만을 활용하여 학습하는 방식으로 우리가 흔히 알고있는 지도학습에서 사용하는 원핫인코딩 방식으로 나온 결과를 의미하고 Soft Target은 Teacher 모델이 예측한 확률 분포를 학습하는 방식으로 좀 더 풍부한 정보를 학습할 수 있다.
Teacher 모델이 예측한 확률 분포를 Student 모델이 학습하는 방법으로 일반적인 지도학습보다 더 풍부한 정보를 제공한다. - 피처 맵 증류(Feature Map Distillation)
Teacher와 Student의 내부 표현을 직접 비교하는 방법으로 LLM에서 내부 히든 레이어를 모방하도록 학습하여 단순한 출력값(Soft Target)뿐만 아니라 중간 과정까지도 학습이 가능하다. - 반대 학습 증류(Inverse Knowledge Distillation)
Student 모델이 스스로 지식을 생성하고 Teacher가 이를 평가하는 방법으로 작은 모델이 먼저 답을 내고, 큰 모델이 피드백을 주는 방법
Knowledge Distillation에 대한 자세한 수식은 추후 공부해서 포스팅하도록 하겠다.
[Summary]

본 논문은 OpenAI의 o1시리즈의 성능을 따라잡기 위해 다양한 시도를 수행했다. 그 중에서 Supervised Fine-tuning 없이 강화학습 만으로 추론 능력을 개발하는 방법을 제시한다.
● R1-Zero
DeepSeek-V3-Base 모델에 GRPO(Group Relative Policy Optimization) 기법을 적용하여 강화학습을 수행한다.
GRPO(Group Relative Policy Optimization)
- 기존의 RL 방식에서는 policy 모델과 동일한 크기의 critic 모델이 필요하지만 GRPO는 critic 모델을 제거하고 group scores를 이용하여 정책을 평가한다.
- 출력 그룹을 샘플링하여 보상을 계산
질문 q에 대해서 이전 정책$\pi_{\theta_{old}}$에서 여러 개의 출력을 생성한다. $$\left\{o_{1}, o_{2}, ... , o_{G}\right\}$$
새로운 정책 $\pi_{\theta}$를 최적화할 때, 출력 그룹의 상대적인 성능을 기준으로 보상을 계산한다.
GRPO 수식

먼저 질문 데이터셋인 $P(Q)$에서 하나의 질문 $q$를 뽑는다. 그리고 해당 질문에 대해서 이전 정책으로 G개의 출력을 생성하여 하나의 그룹으로 생성한다. 그리고 아래의 손실 함수를 최소화하는 방향으로 학습한다.
GRPO 최적화 수식
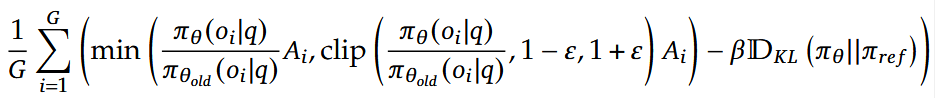
자세히 살펴보면 크게 세 가지 부분으로 나누어 볼 수 있다.
- 이전 정책 출력과 현재 정책 출력의 차이를 비교하는 부분
이 부분은 현재 정책 $\pi_{\theta}$가 주어진 출력 $o_{i}$에 대해 이전 정책 값과 얼마나 다른지를 측정한다.
뒤의 $A_{i}$는 Advantage로 강화학습에서 특정 행동이 평균보다 얼마나 나은지를 나타내는 값이다. 응답이 평균보다 더 나은지 여부에 따라 확률을 얼마나 증가할지 감소할지 결정하는 데 영향을 끼친다. - clip() 부분
정책이 한 번에 많이 변경되지 않도록 방지하는 역할이다. 비율을 $1-\varepsilon, 1 + \varepsilon$으로 제한하여 모델이 단일 보상에 치우쳐서 최적화되지 않도록 한다. - $\beta \mathbb{D}_{KL}$ 부분
KL Divergence식으로 현재 정책과 기준 정책 간의 차이를 측정하는 함수이다. Lasso 또는 Ridge에서 규제를 두는 것처럼 현재 정책과 기준 정책의 차이가 크면 값이 커지고 그만큼 페널티를 주게 된다. 이 과정을 통해 학습이 급격하게 변하지 않도록 조정한다.
$\beta$는 이 규제의 강도를 나타내고 $\mathbb{D}_{KL}$은 현재 정책과 기준 정책의 확률분포가 얼마나 다른지를 측정하는 지표이다.
구체적인 수식은 다음과 같다.
$$\mathbb{D}_{KL}(\pi_{\theta}||\pi_{ref}) = \frac{\pi_{ref}(o_{i}|q)}{\pi_{\theta}(o_{i}|q)} - log\frac{\pi_{ref}(o_{i}|q)}{\pi_{\theta}(o_{i}|q)} - 1 $$
Advantage Function
$A_{i}$는 다음과 같이 계산한다.
$$ A_{i} = \frac{r_{i} - mean(\left\{r_{1}, r_{2}, ... , r_{G}\right\})}{std(\left\{r_{1}, r_{2}, ... , r_{G}\right\})} $$
$ r_{i} $: 현재 출력 i 번째의 보상값
Advantage Function은 그룹 내 평균 보상보다 특정 출력의 보상이 얼마나 높은 지를 정규화하여 평가하는 값으로 보상 값이 높은 출력을 더 자주 생성하도록 모델을 학습한다. 결국 새로운 정책에서는 상대적으로 더 나은 출력을 생성할 확률이 증가한다.
Reward Modeling
DeepSeek-R1-Zero에서는 두 가지 Rewarding 방법을 적용하였다.
- Accuracy Rewards : 모델이 생성한 답변이 맞을 경우에 reward를 제공하는 방법. 예를 들어, 수학 문제에 대한 답변은 정답이 정해져 있으므로 확실한 reward를 제공할 수 있다.
- Format Rewards : Accuracy Rewards에 더해 '<think>'와 '</think>' 태그로 본인이 한 답변에 대해 다시 생각해보는 프로세스를 통해 Rewards를 제공하는 방법을 채택하였다.
추가적으로 본 모델에서는 Neural Reward Model을 채택하지 않았는데 그 이유로 모델이 보상을 속여서 높은 점수를 받는 방향으로 학습하게 되는 Reward Hacking과 결국 Neural Reward Model도 학습하려면 GPU 연산량이 증가한다는 이유로 채택하지 않았다고 한다.(GRPO 만으로도 강화 학습이 가능)
학습 과정에서는 DeepSeek-V3를 기반으로 강화학습만을 통해 학습하였는데 강화 학습 과정에서 아무 형식 없이 자유롭게 학습하게 되면 평가에 어려움이 있으므로 기본적인 답변 형식을 정의하는 템플릿을 제공하여 모델의 출력을 일정한 구조로 만들어서 평가하였다.

Self-evolution Process
DeepSeek-R1-Zero는 강화학습이 모델을 어떻게 학습하고 있는지 지속적으로 확인할 수 있다고 한다. 이를 통해 모델이 시간이 지남에 따라 어떻게 진화하는 지 확인하여 특히 복잡한 추론 문제를 해결하는 과정을 확인하였다고 한다.

Reflection
또한 이 방법의 가장 놀라웠던 점으로 Reflection을 꼽았는데, Reflection은 모델이 이전에 생성한 답변에 대해 해당 답변에 대해 다시 생각하고 평가하여 더 나은 답변을 생성하는 과정이다. 본 연구에서 이 reflection 기능에 대해 코딩하지 않았는데 RL으로 학습하는 과정에서 모델이 생성한 답변을 스스로 평가하는 기능으로 추론 능력을 더욱 향상 시켰다고 한다.
Aha moments

Aha moments는 DeepSeek-R1-Zero에서 모델이 스스로 복잡한 추론 능력을 개발하는 순간들을 의미한다. 위 예시처럼 답변을 생성하다가 "Wait, wati. Wait., ..." 이런 식으로 본인의 답변에서 aha moment를 통해 더 큰 보상을 받기 위해 스스로 학습하는 과정으로 DeepSeek-R1-Zero가 더 복잡한 추론 문제를 해결하는 능력을 개발할 수 있었다.
한계점
DeepSeek-R1-Zero는 OpenAI-o1-mini를 능가하는 성능을 보여주었다([Results] 참고). 하지만 본 논문에서는 Zero 버전의 한계를 다음과 같이 정의하였다.
- 가독성 문제 (Poor Readability)
DeepSeek-R1-Zero의 응답이 명확하지 않거나 인간이 읽기에 부적절한 경우가 많았다.
답변이 너무 길어지거나 불필요한 정보가 포함되는 경향이 있었다. - 언어 혼합
특정 질문에 대해 영어와 중국어가 혼합되어 출력되는 문제가 발생하였다. -> RL 과정에서 높은 점수를 받는 응답이 언어적으로 일관되지 않았기 때문 - 출력 형식의 불안정
추론 과정과 최종 답변이 명확하게 구분되지 않는 경우가 발생하였다.
● R1
DeepSeek-R1-Zero의 한계에 해당 연구팀은 두 가지 의문점을 발견하였다.
1. cold start data를 미리 주어진다면 추론 능력이 더 향상될 수 있을까?
2. 사용자가 사용하기 편한 모델로 훈련시키려면 어떻게 해야할까?
DeepSeek-R1-Zero의 한계를 극복하고 두 가지 과제를 해결하고자 DeepSeek-R1 모델을 개발하게 되었다.
Cold start
DeepSeek-R1-Zero와 달리 수 천개의 Cold start data로 DeepSeek-V3-Base 모델을 fine-tuning한 후 강화학습을 수행하였다. Cold start data로는 논리와 관련된 데이터들을 사용하였다. 본 논문에서는 Cold start data를 추가하면서 두 가지의 장점을 얻었다고 한다.
- 가독성 : 모델이 답변을 생성할 때 Zero 버전은 언어 혼합의 문제와 가독성 문제가 발생하였는데 Cold start data를 추가하고, 특정 형식으로 답변을 생성하도록 하여 사용자가 더 잘 이해할 수 있는 답변을 생성하였다고 한다.
- 성능 : Cold start data를 추가하고 그에 맞는 형식을 제공함으로써 DeepSeek-R1-Zero보다 더 나은 추론 성능을 보여주었다고 한다.

Cold start data로 fine-tuning한 후에 동일하게 강화학습으로 학습하였는데 입력 프롬프트에 언어가 혼합 사용되었을 경우에 CoT에서 언어 혼합을 확인할 수 있었다고 한다. 이 문제는 한 가지 언어로만 답변할 경우에 보상을 주어 해결하였다.
강화 학습을 수행한 후에는 다시 fine-tuning을 수행하였다. 이전에는 논리와 관련된 데이터를 fine-tuning하였다면 이번 fine-tuning에는 사용자 친화적인 모델을 위해 Writing, Role-Playing 등 일반적인 목적에 부합하는 데이터로 fine-tuning하였다.
Fine-tuning 후에는 다시 강화 학습을 수행한다. 이번에는 사용자에게 더 도움이 되는 답변을 생성하고 위험한 답변은 생성하지 않도록 강화학습을 수행한다. 이전에 cold start data로 fine-tuning 후에 강화학습을 수행할 때는 DeepSeek-R1-Zero에서 사용한 rule-based reward 방식을 사용하였는데 이번에는 reward model을 사용하여 강화학습을 수행하였다.
● Distillation
[Background]에서 설명한 것처럼 큰 모델에서 얻은 좋은 학습 결과를 더 작은 모델이 최대한 비슷한 성능을 재현하도록 하는 방법으로 현재 개발된 소형 언어 모델에서도 R1의 성능을 나타내기 위해 Distillation을 적용하였다. 여기서 연구자들은 SFT만 적용하고 강화 학습은 적용하지 않았는데 이는 Distillation의 성능을 보여주기 위함으로 강화 학습을 추가로 적용하는 것은 추후 연구로 남겨두었다고 한다.
[Results]
● R1-Zero

R1-Zero와 OpenAI의 모델의 비교이다. R1-Zero가 몇몇 지표에서 OpenAI의 o1-mini의 성능을 뛰어넘는다는 것을 보여준다.
● Baseline Models
Claude-3.5, GPT-4o, DeepSeek-V3, OpenAI-o1-mini, OpenAI-o1-1217
● 평가지표
평가지표는 너무 많아 결과표를 참고하길 바란다.
●R1 실험 결과

결과를 보면 DeepSeek-R1과 OpenAI-o1-1217이 대부분의 지표에서 좋은 성능을 보인다는 걸 알 수 있다. DeepSeek-R1은 강화학습으로 OpenAI-o1의 성능을 따라잡고 더 뛰어난 점도 보여주었다.
● Distillation Models

지식 증류한 모델들의 실험 결과이다. DeepSeek-R1의 성능에는 미치지 못하지만 그래도 파라미터 수에 비해 좋은 성능을 보였다. 심지어 OpenAI-o1-mini의 성능을 능가하였다.
● Discussion
본 논문에서는 지식 증류와 강화학습의 결과를 비교해보았다. 위의 결과를 보면 알 수 있듯이 R1 모델을 작은 모델에 지식 증류한 것이 엄청 좋은 성능을 보이기 때문이다. 근데 여기서 의문점이 하나 있다. 그렇다면 그 작은 모델을 강화학습하는 것이 지식 증류보다 더 좋은 성능을 보이는지 확인해야 한다. 그래서 연구팀은 Qwen을 강화학습만 수행한 것과 지식 증류한 것의 성능을 비교해보았다.

결과는 지식 증류한 것이 더 좋은 성능을 보여준다. 이를 통해 작은 모델을 강화학습하여 자체적으로 학습하는 것보다 지식 증류를 사용하는 것이 더 경제적으로도 효과적이고 성능도 더 뛰어나다는 것을 알 수 있다.
● 성공하지 못한 시도
강화 학습의 방법으로 Process Reward Model 방법과 Monte Carlo Tree Search 방법을 적용하여 실험을 진행해보았는데 두 방법 모두 좋지 못한 결과를 얻었다고 한다. 자세한 내용은 논문 본문을 참고하기 바란다.
[Conclusions]
본 논문은 강화학습을 활용하여 모델의 추론 능력을 향상시키는 연구에 대한 결과를 공유하였다. 또한 강화학습을 활용하여 OpenAI-o1과 비슷한 성능을 보이는 모델을 개발하였다. 다양한 작은 모델로 지식 증류하는 방법으로 높은 성능을 기록하였다. 하지만 아직 R1 모델의 한계점에 대해 다음과 같이 제시한다.
- 일반적 능력 개선
R1은 V3보다 함수 호출, 다중 회화, 복잡한 역할 수행, JSON 출력에서 성능이 떨어진다. 이를 Long CoT를 활용하여 개선한다고 한다. - 언어 혼합 문제 해결
현재 중국어와 영어에 최적화 되어있어, 다른 언어 사용 시 혼합 문제가 발생한다. - 프롬프트 엔지니어링 개선
Few shot prompting에 민감하며 오히려 Zero-shot prompting이 더 좋은 성능을 보여준다. - 소프트웨어 엔지니어링 작업 강화
현재 강화학습 평가 시간이 길어 소프트웨어 엔지니어링 작업에서 V3 대비 큰 성능 향상이 없다.
DeepSeek-R1은 강화학습을 활용한 강력한 모델이지만 아직 몇 가지 개선할 부분이 남아 있으며, 향후 연구에서 이를 해결할 계획이라고 한다.
논문이 발표된 지 며칠이 지나서 리뷰하지만 엄청난 발견이 있는 논문이다. 이 논문은 OpenAI의 o1의 성능을 뛰어넘었다는 기사를 보고 읽었는데 막상 살펴보니 내 생각으로는 o1과 비슷한 성능을 보여준다고 생각했다. 물론 o1의 파라미터 수가 공개되진 않았지만 아마 o1의 파라미터 수 보다 적은 양으로 비슷한 성능을 보여준다는 것은 정말 주목해봐야할 논문이라고 생각한다. 또 한가지 드는 의문은 지식 증류라는 기법이 작은 모델에 큰 부담 없이 큰 모델이 얻은 지식을 알려주어 큰 모델과 근접한 성능을 보여준다면 과연 o1을 증류한다면 누구나 개인 비서를 데리고 다니는 시대가 올 수 있다고 생각한다.
또 신기한 것이 해당 논문이 발표되고 언론의 주목을 받으면서 엔비디아의 시가 총액 약 800조가 증발해버렸다. 그런데 한번 생각해보면 이 논문에서 개발한 모델은 물론 성능이 적은 GPU를 사용하여 모델을 개발하였지만 더 좋은 성능을 보여주기 위해서는 더 큰 모델의 개발이 이루어져야 한다고 생각한다. 본 논문에서 보여준 것처럼 더 좋은 성능의 큰 모델들이 개발된다면 작은 모델이 자체적으로 강화학습으로 학습하는 것보다 큰 모델이 얻은 지식을 증류하는 것이 더 나은 성능을 보여줌으로써 개개인이 사용할 더 좋은 인공지능 비서를 위해서라면 더 똑똑하고 큰 모델의 개발이 불가피하다고 얘기하고 싶다.